Share
What Is Kubernetes?
Kubernetes is a free, open-source orchestration solution. It was initially developed by Google for the purpose of managing containerized applications or microservices across a distributed cluster of nodes.
Kubernetes offers a highly resilient infrastructure designed for zero downtime deployment, with capabilities such as scaling and automatic rollback. Kubernetes also provides self-healing capabilities of containers, including auto-placement, auto-replication, auto-restart, persistent storage management, and scaling based on CPU usage.
While Kubernetes was originally intended for stateless applications, in recent years it is increasingly used for stateful workloads, which requires users to deploy databases on Kubernetes. Two common ways to manage databases on Kubernetes are using StatefulSets and DaemonSets.
In this article:
- Orchestrating Databases in Kubernetes: StatefulSets vs DaemonSets
- Running SQL Databases on Kubernetes
- Tips for Running Your Database on Kubernetes
- Kubernetes Database with NetApp Cloud Volumes ONTAP
Orchestrating Databases in Kubernetes: StatefulSets vs DaemonSets
There are two main options for orchestrating databases in Kubernetes: via StatefulSets or DaemonSets.
StatefulSets
A StatefulSet is a group of pods with persistent identities and stable hostnames, designed to run stateful and replicated Kubernetes services. Kubernetes maintains the pods in a StatefulSet whether they are scheduled or not. The set has persistent disks where resilient data such as state information for each pod is stored.
Kubernetes provides the Persistent Volumes (PV) feature—local persistent volumes can serve as local disks attached directly to Kubernetes nodes.
Each StatefulSet pod has a persistent ID that allows Kubernetes to run a replicated database. The ID is unique and persists even if the pod has been rescheduled to a different machine. This means you can attach specific volumes to pods, and the state of the pods will be retained when they are moved across the data center.
Performance implications for StatefulSets include the fact that the database runs on the same machine as Kubernetes, which means that both consume the same resource and impact performance. Kubernetes services can compete with stateful services for resources.
Read our blog: Managing Stateful Applications in Kubernetes
DaemonSets
A DaemonSet is a service that makes sure a pod is running across all nodes. For instance, you can create a DaemonSet on a cluster with five nodes, and the DaemonSet will schedule a total of five pods. This allows you to run a database on a specific set of nodes, with Kubernetes ensuring that the database will always remain available. This is useful for stateful services as you don’t need to run anything else on the database nodes.
DaemonSets also use local disks more reliably, because you don’t need to reschedule the database pods or worry about losing disks. However, it should be noted that local disks are relatively prone to failure, given that they generally lack redundancy and replication.
Performance implications for DaemonSets include the fact that the database occupies an entire set of nodes, which limits the number of connections between your database and other applications. This helps reduce resource dependencies and improve database security.
Example: Running SQL Server Databases on Kubernetes
You can run Microsoft SQL Server on Kubernetes using official SQL Server container images - which now support Ubuntu, Windows, and Red Hat Linux. These container images provide the necessary files for the SQL Server engine, including the server agent, command-line tools and built-in features such as replication.
Deploying a SQL Server database on Kubernetes offers benefits such as:
- No need to install after starting up the container
- Portability over various environments
- Ease of use (i.e., to start, stop or update)
- Isolation of services for enhanced security
You can use a variety of storage types as persistent volumes, including AWS EBS volumes, Google Cloud Engine persistent disks, Azure Disks and Azure Files.
The following diagram outlines how these components are deployed in a single Kubernetes cluster for a Microsoft SQL Server database:
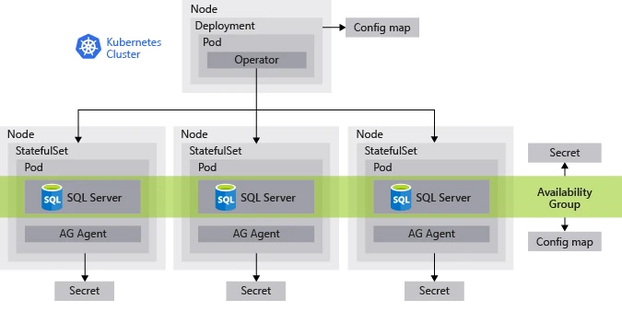 Image Source: Microsoft
Image Source: Microsoft
Tips for Running a Database on Kubernetes
When you choose to adopt Kubernetes, you should consider the type of database you want to run and how well it will perform in the new environment, given the different limitations. For instance, there is a higher likelihood of failover events in Kubernetes compared to traditionally hosted or fully-managed databases, because pods are occasionally shut down and replaced.
Consider the following:
- Database type—the database will be easier to run on Kubernetes if it has built-in concepts such as failover elections, sharding and replication (examples include Elasticsearch, MondoDB and Cassandra). Open-source projects often provide customizable resources or operators to help you manage your database.
- Functionality—consider also the function of your database and how it relates to your business needs. Kubernetes favors databases that store more caching and transient layers. These kinds of data layers tend to offer more built-in resilience for applications, which improves the overall experience.
- Added features—you can wrap SQL databases with more accessible features on Kubernetes, using operators, which are a method of packaging Kubernetes that allows you to manage and monitor your stateful applications more easily. You can use the Operator Framework for coreOS to create your own custom operators.
- Replication mode—it is important to understand the available replication modes available in your database. Asynchronous replication modes pose a greater risk of data loss, because a transaction can be committed to your primary database but not to a secondary database. Make sure you understand the risk level, considering the acceptable level of data loss risk given the context of the application.
Kubernetes Database Storage with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP capacity can scale into the petabytes, and it supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
In particular, Cloud Volumes ONTAP supports Kubernetes Persistent Volume provisioning and management requirements of containerized workloads.
Learn more about how Cloud Volumes ONTAP helps to address the challenges of containerized applications in these Kubernetes Workloads with Cloud Volumes ONTAP Case Studies.
Learn How to Set Up MySQL Kubernetes Deployments with Cloud Volumes ONTAP.

