Share
Snapshot technology has been integral to protecting data both in the on-prem data center and in the cloud. AWS snapshots come in the form of Amazon Elastic Block Storage snapshots.
In this post we’ll take a closer look at the anatomy of these AWS snapshots and their key use cases, first by giving an overview of cloud storage snapshots in general and then delving into the specifics of this data protection technology for AWS EBS storage volumes.
Introduction to Storage Snapshots
Storage snapshot technology is used for creating point-in-time references to data that resides in the underlying storage volume. The main use case for snapshots is for data protection. Typically, the content of a storage snapshot is read-only and can be used by storage admins and various third-party backup applications to read or restore data, while the write activities carry on uninterruptedly to the live storage volume.
Storage Snapshot Types
Copy-on-write Snapshots
With copy-on-write snapshots, a dedicated storage capacity is reserved for snapshot data. This storage capacity will hold all the metadata (such as information about where the original data resides in the file system) plus a copy of the original data whenever changes occur to the original data blocks.
These snapshots are quick to create due to the fact that normally most data blocks only need a metadata copy operation during snapshot creation. However, as and when the original data blocks are updated or overwritten by the active file system, the contents of the original data blocks are copied over to the snapshot location in the background. That can have a performance impact on subsequent write operations to the original blocks after the snapshot has been created due to having to wait for the original data blocks to be copied over to the snapshot location.
Redirect-on-Write Snapshots
Similar to copy-on-write snapshots, but instead of copying the original data to the snapshot location as and when updated, the original data stays as is and the changes to those blocks are redirected and written to the location set aside for snapshots and the metadata is updated to point the active file system to the new blocks, as necessary. This method has the lowest write penalty. Multiple snapshot creations and subsequent snapshot deletion can lead to complexity, often extensified when the original data set becomes fragmented.
Split-Mirror (AKA Clone) Snapshots
Creates an identical copy of the source data volume, file system, or LUN during the creation of the snapshot. Due to the data copy operation, snapshot creation can be time consuming as consumes twice the amount of storage capacity.
CDP (Continuous Data Protection) Snapshots
This type of snapshot offers continuous backup of data whereby changes to the source data are continuously and automatically captured and stored in a separate location.
Application-Consistent Vs. Crash-Consistent Snapshots
When it comes to storage snapshots that are typically taken at the storage system layer, the data held in the storage volumes needs to be consistent with the operating system and the applications using it, as well as being usable for recovery purposes. In order to ensure these things, most snapshot-capable storage solutions provide crash-consistent or application-consistent snapshot capabilities.
Crash-Consistent Snapshots
Crash-consistent snapshots are typically taken to ensure the consistency of the files (within the guest operating system level). Crash consistency typically means the individual files committed and saved to the disk and their dependencies are consistent such that any point-in-time snapshot taken at the storage layer will have the same state as a file system on a server / VM that was crashed or powered off without a graceful shutdown. Backup software that utilises crash-consistent snapshots typically relies on Microsoft Volume Shadow Copy (VSS) capability for Windows systems to ensure pending IO is frozen in order to ensure guest OS file level consistency of data on disk. Crash consistency will not ensure any application-specific consistency; therefore, crash-consistent snapshots may not provide a sufficient solution for application-specific files such as database files, when it comes to protection and recovery.
Application-Consistent Snapshots
By nature, application-consistent snapshots are also crash consistent, but on a much deeper level. An application-consistent snapshot will ensure that the application accessing the data is aware of the snapshot being taken at the storage layer and thus, the data is application consistent on the storage volume prior to the snapshot being taken. This will ensure that the outstanding IO activities in memory are flushed to the disk and the data committed to the storage volume is consistent with the application. In this way during a recovery scenario, the data is readable by the application (i.e., SQL, Oracle, etc.). This function is often a prerequisite for database application snapshots.
Introduction to AWS Snapshots
Amazon Elastic Block Storage (Amazon EBS) is a block-level storage construct that provides durable, highly available storage for Amazon EC2 instances. Amazon EBS volumes are typically created within an AWS Availability Zone (AZ) where the content of the EBS volume is replicated within the AZ. Amazon EBS storage is recommended to be used for file systems, databases, or any application that requires access to unformatted, granular block level storage access.
What Is an AWS Snapshot?
Amazon EBS snapshots provide long-term data protection and durability for data held on EBS volumes and can also be used for replicating data across various AWS regions as well as starting new Amazon EBS volumes. The AWS architecture ensures that these copy-on-write snapshots contain all the incremental changes as well as all the metadata required within the same snapshot itself. During an EBS snapshot creation process, snapshot data is transferred in to Amazon S3 storage buckets (managed by AWS & Not visible to the end user) as an automated background task.
Key AWS Use Cases for Snapshots
There are various use cases for using EBS snapshots on AWS. Some of these include:
- Data backup: Amazon EBS snapshots are the AWS-recommended way to take off-site, off-AZ, or off-region data AWS backups for Amazon EC2 instances and their data volumes. Amazon EBS snapshots provide a convenient way to snapshot a running EC2 instance along with its data that is automatically moved out of the EBS volume to Amazon S3 for long term retention. Various third-party backup solutions also leverage these snapshots during their backup process to protect EC2 instances.
- Disaster recovery: Amazon EBS snapshots can be leveraged to enable data replication to various other AWS regions in order to provide a DR capability for the Amazon EC2 instances using the snapshot copy capability.
- Dev/test: Amazon EBS snapshots can also be leveraged to meet various data cloning requirements. Creating dev/test clones of various production Amazon EC2 instances can now be streamlined through the use of creating EBS volume copies through snapshots.
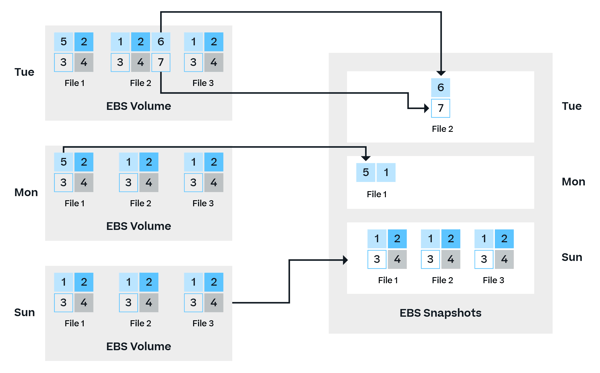
How Amazon EBS Snapshots Work
Creating & Deleting EBS Snapshots
Amazon EBS provides the ability to take point-in-time, crash-consistent snapshots, either per volume or across multiple EBS volumes attached to an EC2 instance. These snapshots can be used for data backup or as a source to create new volumes.
An EBS snapshot can be created using the console, using the create-snapshot command AWS CLI, or using the New-EC2Snapshot commandlet (AWS Tools for Windows PowerShell).
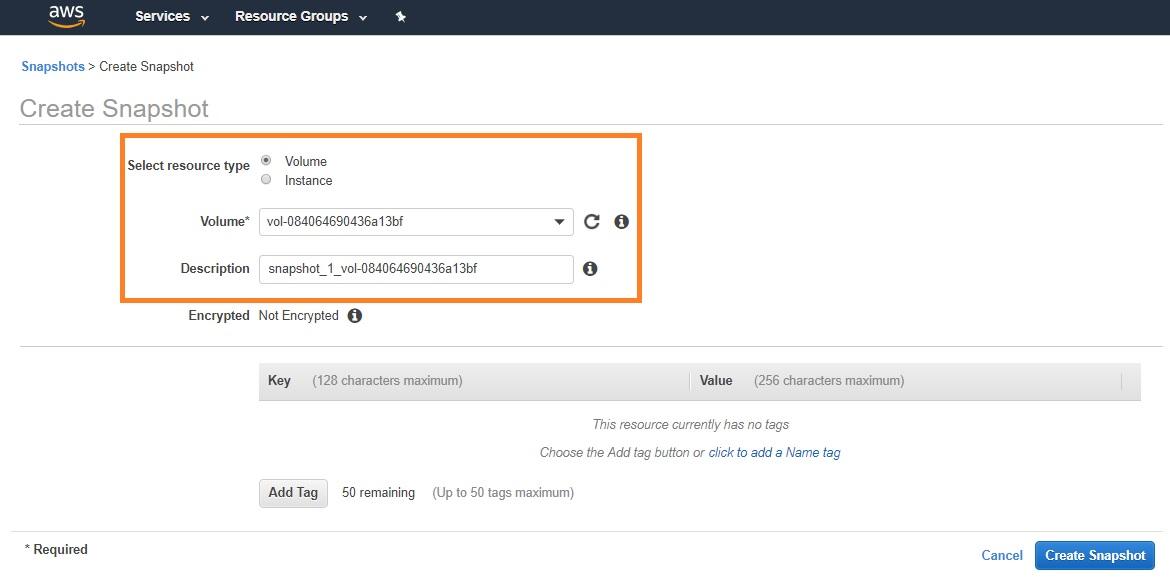
During the creation of the baseline snapshot of an Amazon EBS volume, the entire data set is copied over to Amazon S3. This can be a time-consuming process that also will require a storage capacity for a complete copy of the original. Subsequent snapshots will only copy and store the changed data while the unchanged data blocks that reside within the baseline snapshot are then referenced by the next snapshot. This cross-snapshot data reference continues to occur down the snapshot chain, which helps reduce the storage footprint consumed by snapshots in order to minimize the organizational storage costs.
Creating a snapshot is typically immediate, however until all the baseline data is fully transferred over to Amazon S3 storage, the status will be in pending mode. This completion time can vary depending on the size of the changed data that needs to be copied over behind the scenes. Multiple pending snapshot creation jobs can have significant performance impacts on the live volume and its data. By default, AWS limits the number of pending snapshots to five for a single gp2, Magnetic tape, or io1 volume, and one pending snapshot for a single sc1 or st1 volume.
It should also be noted that Amazon EBS snapshots are crash consistent only and are not application consistent. Amazon EBS volumes attached to instances with critical applications such as databases would typically require application consistent snapshots in order to preserve the integrity of the application data for AWS database backup. Such volumes would either require the instance to be turned off or the application data to be consistently written to the EBS volume prior to a graceful shutdown of the application and the volume to be dismounted, before an application consistent snapshot is created.
Deleting snapshots can be carried out using the console or the delete-snapshot command as well as Remove-EC2Snapshot PowerShell commandlet. Note that if an EBS volume has more than one snapshot in the chain, the deletion of a snapshot may not necessarily reduce the storage consumption by the full size of that snapshot. This is because the cross-snapshot data references that could be in place (as described above).
To protect snapshots, AWS has introduced a fully managed backup service that allows you to backup several types of resources, one of which is EBS, called AWS Backup. It’s a pretty straightforward service that allows you to create a backup plan with a rule that determines the frequency and retention of the backup for one or more resources that you wish to back up. In the case of EBS, AWS Backup lets you create backup policies to determine the frequency with which snapshots are created and how long they should remain available before automatically being deleted.
Amazon EBS Snapshot Copying and Sharing
It is possible to copy Amazon EBS snapshot data across AWS regions. While this provides an easy data migration / replication option for customers, it should be noted that the first snapshot copy will be a full copy of the source snapshot consuming an equal amount of underlying storage with the associated storage costs. Any further snapshot copies will be incremental copies.
Snapshots can be copied across regions using the Amazon EC2 console or the copy-snapshot command (AWS CLI). These copied snapshots can then be leveraged to create volumes which can be attached to new Amazon EC2 instances within the destination AWS region for data access.
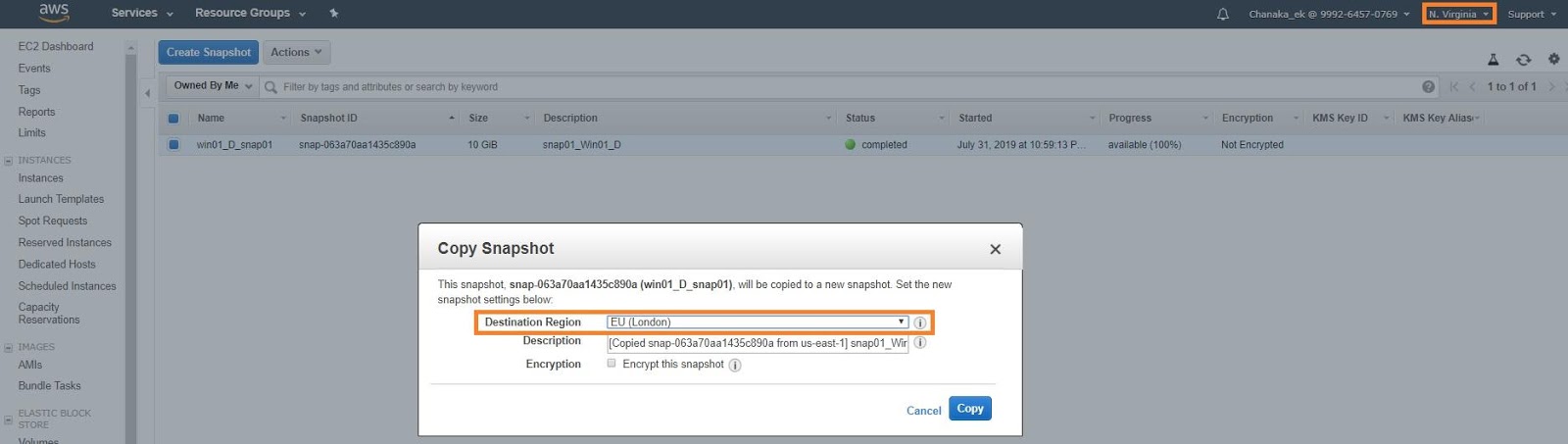 Copying an Amazon EBS snapshot.
Copying an Amazon EBS snapshot.
Amazon EBS snapshots can also be shared with other AWS users via modifying the permissions of a snapshot. The snapshots can also be made public. If made public, note that all data stored under the snapshot will then be accessible by anyone.
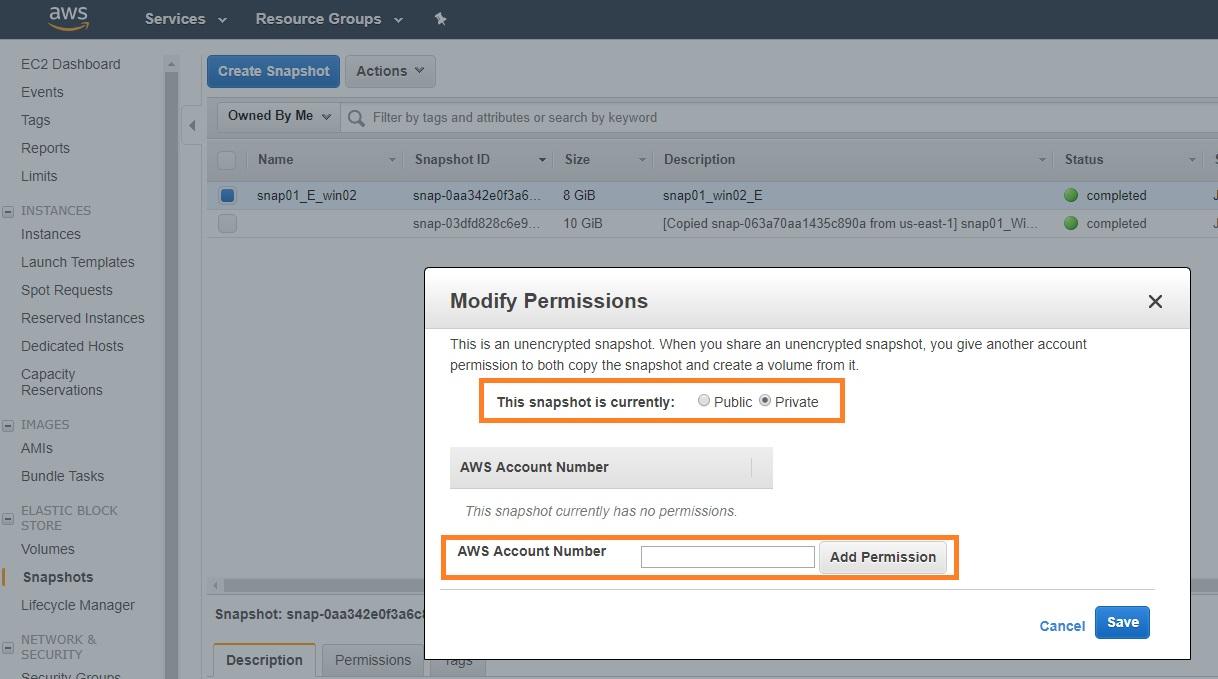 Modifying snapshot permissions.
Modifying snapshot permissions.
Restoring from an Amazon EBS Snapshot
Each Amazon EBS snapshot can be used to restore data, given sufficient permissions and knowing the snapshot ID. This provides the protection against malicious or accidental damage to data, both at the individual file level and at the entire volume level.
Restoring data from an Amazon EBS snapshot involves the following steps,
- Creating a brand new Amazon EBS volume using an existing snapshot.
- Attaching the new Amazon EBS volume to an Amazon EC2 instance.
- Copying or restoring data within the guest file system OR resuming the application (if replacing the old volume).
When creating the new Amazon EBS volume from a snapshot, the volume is created and made available to immediately access the data. The data loading (initialization) to the new EBS volume from the Amazon S3 bucket hosting the snapshot is done as a background task (AKA: lazy loading). That can be time consuming depending on the size of consumed data set within the snapshot.
If the Amazon EC2 instance requests a data block that is not yet transferred over from the Amazon S3 bucket to the new EBS volume, those blocks are fetched directly from the Amazon S3 bucket behind the snapshot. This could introduce a significant IO latency overhead during this first read. This can be avoided by forcing an immediate initialization of the entire volume using dd (Command line utility for file copy and conversion purposes) or fio (Flexible IO tester, a Linux utility for IO workload simulation and benchmarking purposes) prior to reading from the new EBS volume. Refer to additional information available for Windows instances and Linux instances.
Provisioning New Amazon EBS Volumes from Snapshots
Creating an Amazon EBS volume from a snapshot involves a lazy loading of the data from the snapshot in Amazon S3 storage to the new Amazon EBS volume, similar to the process mentioned above. Therefore, reading operations from the new EBS volumes could be subjected to the same latency challenges if the data initialization hasn't been completed.
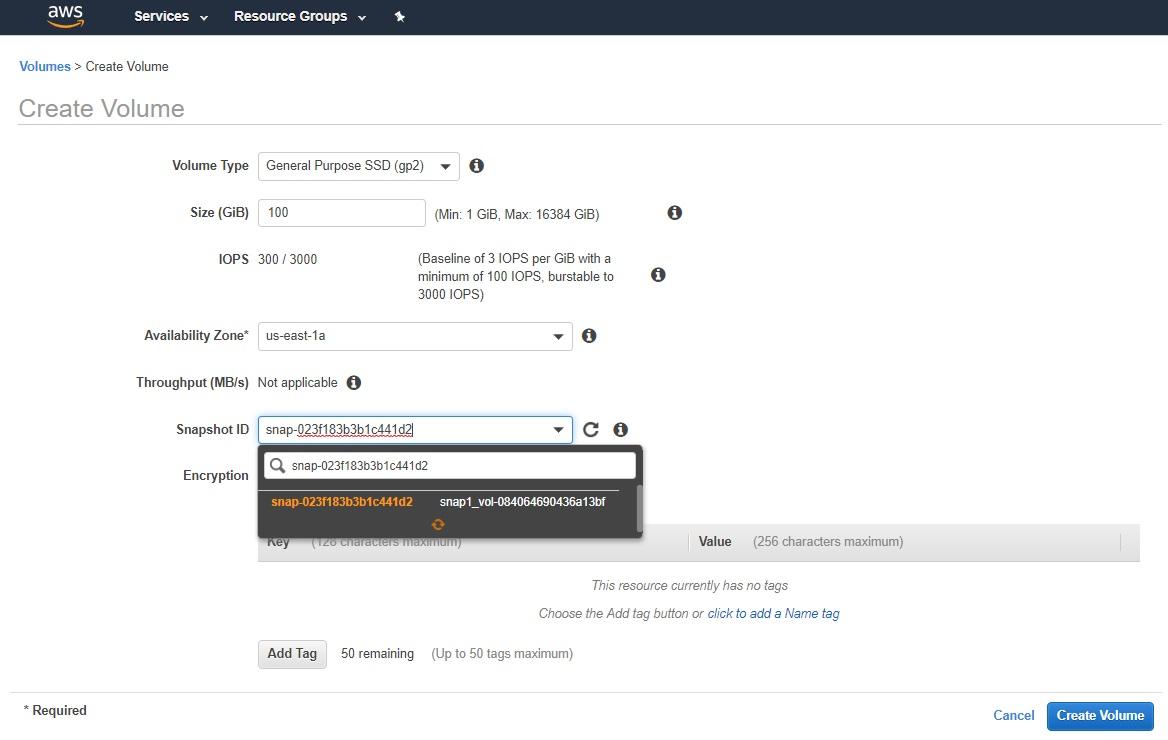 Creating a new Amazon EBS volume from a snapshot.
Creating a new Amazon EBS volume from a snapshot.
Final Note
AWS snapshots for EBS volumes provide a good solution for customers to protect and efficiently store their Amazon EC2 instances and the data behind them. The API-driven capabilities enable various DevOps capabilities where data protection and data manipulation activities can be orchestrated on demand or based on events (through integration with AWS Lambda).
But the drawbacks of lazy loading and the full initial copy of the snapshot can be avoided by users who are deploying Cloud Volumes ONTAP for AWS for certain use cases. Using NetApp Snapshot™ technology, Cloud Volumes ONTAP and is able to reduce the time it takes to create and to store snapshot data. This data is stored even more efficiently when the powerful NetApp storage efficiencies are applied to the original copy.

AWS Snapshots Q&A
How Much Do AWS Snapshots Cost?
EBS snapshots are offered at different costs across different regions. In the US-East region, for example, snapshots are billed at a flat cost of $0.05 per GB per month. In the EU (London) region snapshots are billed at $0.053 per GB per month.
Can I Delete AWS Snapshots?
Yes, you can delete a snapshot via the AWS Management Console. Here is how to do this:
- Go to the Amazon EC2 console
- Go to the navigation pane and choose the Snapshots option
- Choose a snapshot
- Find the Actions list
- Choose Delete
- Click Yes, Delete
What is the Difference Between Image and Snapshot?
In Amazon EC2, an Amazon Machine Image (AMI) backs up an entire server including all attached EBS volumes. A snapshot is a point in time copy of a certain volume. You can take snapshots of your EBS volumes and save them in S3 storage.
Learn More about AWS Snapshots
Read more about these snapshot benefits and other articles in our full series on AWS snapshots:
Understanding AWS Snapshot Pricing: Data Transfer and Storage Costs
AWS snapshots are frequently used to backup and restore Amazon EC2 data. There are different factors that affect EBS snapshot pricing. It’s important to get to know these and take them into account in order to mitigate your cloud costs.
This post looks at some of the major parameters that affect snapshot pricing, such as transfer to S3, encryption, incremental backup and region. It breaks down pricing into transfer fees and storage costs on Amazon S3, giving concrete detailed examples. Finally, the article also shows you how Cloud Volumes ONTAP can help significantly reduce these costs.
Read “Understanding AWS Snapshot Pricing: Data Transfer and Storage Costs” here.
The S3 Outage: Be Prepared for Unavoidable Cloud Failures with AWS Snapshots
Think the cloud can’t fail? The major AWS outage of 2017 was a sign that no matter how much confidence we have in the cloud, users still need to have contingency plans in case the entire cloud infrastructure comes crashing down, taking your sites and applications with it.
Users do have options. Turning to NetApp cloud solutions can help protect your data and make sure that you can operate and recover from the worst cloud outages.
Read more in “The S3 Outage: Be Prepared For Unavoidable Cloud Failures with AWS Snapshots” here.
NetApp SnapMirror Data Replication with AWS
Anyone who is familiar with NetApp storage systems in the data center knows SnapMirror data replication makes it easy and fast to transfer and replicate data between storage repositories. This powerful feature is also a key part of using storage in the cloud with Cloud Volumes ONTAP. SnapMirror is integral to migrating to the cloud, managing a disaster recovery solution, and orchestrating hybrid or multicloud environments.
SnapMirror is based on NetApp’s highly efficient snapshot technology, which consumes less storage and thus costs less than using AWS snapshots via Amazon EBS. You’ll also see how SnapMirror can migrate snapshots that are application consistent though integration with NetApp SnapCenter®.
Read more in “NetApp SnapMirror Data Replication with AWS”
Deep Dive into Azure and AWS EBS Snapshots
While the article you just read covered AWS snapshots on their own, in this article we take a look at how AWS snapshots and Azure snapshots work stacked up against each other. What are the key differences between these two technologies? And are either of them adequate to meet your enterprise-level data protection requirements?
Read more in “Deep Dive into Azure and AWS EBS Snapshots” here.
Storage Snapshots Deep Dive: Cloud Volumes Snapshots
You’ve heard a lot about AWS snapshots, but in this article we take a deep dive into NetApp Snapshot technology and how Cloud Volumes uses it to make cloud deployments with AWS and Azure less expensive and better protected. In this article, we take a deep dive into how this technology operates.
NetApp Snapshots are built on the WAFL (Write Anywhere File Layout) technology innovated by NetApp. How does WAFL work and what does it do? In this article you’ll learn that and more, such as how snapshots underpin several of the technologies used by Cloud Volumes ONTAP, from SnapMirror data replication and SnapVault data archiving, to data cloning with FlexClone® and data restoration with SnapRestore.
Read “Storage Snapshots Deep Dive: Cloud Volumes Snapshots” here.
Crash-Consistent Backups for Applications in the AWS Cloud
Understanding how crash-consistent backups work means understanding why they’re so important. For enterprises, these reasons mainly come down to the recoverability of their line of business applications that users rely on. When users update data to crucial databases while backups are being created, that information must be stored or else it will be at risk of being lost if there is ever a need to restore from that backup. But there are also strict compliance regulations that require such backups be created and stored for specific periods of time, such as in the healthcare and financial industries. In either case, the financial impacts can be serious.
In AWS, the responsibility for your operation is split between you and Amazon. When it comes to making sure that data is consistently backed up in AWS, the responsibility falls to the user. Find out in this post the various methods for achieving quiescence in order to create crash-consistent backups for your databases and other applications that run on AWS services.
Read “Crash-Consistent Backups for Applications in the AWS Cloud” here.
See Additional Guides on Key Cloud Storage Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of cloud storage.
File Upload
Authored by Cloudinary
- Angular File Upload to Cloudinary in Two Simple Steps
- Uploading PHP Files and Rich Media the Easy Way
- AJAX File Upload - Quick Tutorial & Time Saving Tips
Cloud File Sharing
Authored by NetApp
- Cloud File Share: 7 Solutions for Business and Enterprise Use
- Solving Enterprise-Level File Share Service Challenges
- Azure SMB: Server Message Block in the Cloud for Azure Files
Multicloud Storage
Authored by NetApp
