Share
High availability is a quality of computing infrastructure that is important for mission-critical systems. High availability permits the computing infrastructure to continue functioning, even when certain components fail.
In this article, we’ll outline a 5-step Azure high availability checklist, which involves defining availability requirements, planning your high availability architecture, deploying applications consistently using Azure's Infrastructure as a Service (IaaS) tools, and more.
In this post, we’ll take a closer look at Azure high availability and show how NetApp Cloud Volumes ONTAP can help.
This is part of an extensive series of guides about FinOps.
In this page:
- What is high availability
- A 5-Step Azure high availability checklist
- Achieve Azure high availability with Cloud Volumes ONTAP
What Is High Availability?
High availability is a quality of computing infrastructure that allows it to continue functioning, even when some of its components fail. This is important for mission-critical systems that cannot tolerate interruption in service, and any downtime can cause damage or result in financial loss.
Highly available systems guarantee a certain percentage of uptime—for example, a system that has 99.9% uptime will be down only 0.1% of the time—0.365 days or 8.76 hours per year. The number of “nines” is commonly used to indicate the degree of high availability. For example, “five nines” indicates a system that is up 99.999% of the time.
The basic elements of high availability
The following three elements are essential to a highly available system:
- Redundancy—ensuring that any elements critical to system operations have an additional, redundant component that can take over in case of failure.
- Monitoring—collecting data from a running system and detecting when a component fails or stops responding.
- Failover—a mechanism that can switch automatically from the currently active component to a redundant component, if monitoring shows a failure of the active component.
Technical components enabling high availability
The following systems are commonly used in highly available systems, and help implement the concepts of redundancy, monitoring and failover:
- Data backup and recovery—a system that automatically backs up data to a secondary location, and recovers back to the source. This can be used to set up redundancy and failover. Learn more in our in-depth guide to Azure backup options.
- Load balancing—a load balancer manages traffic, routing it between more than one system that can serve that traffic. The load balancer can be aware that one of the target systems has failed, and redirect traffic to another available system, thus implementing monitoring and failover.
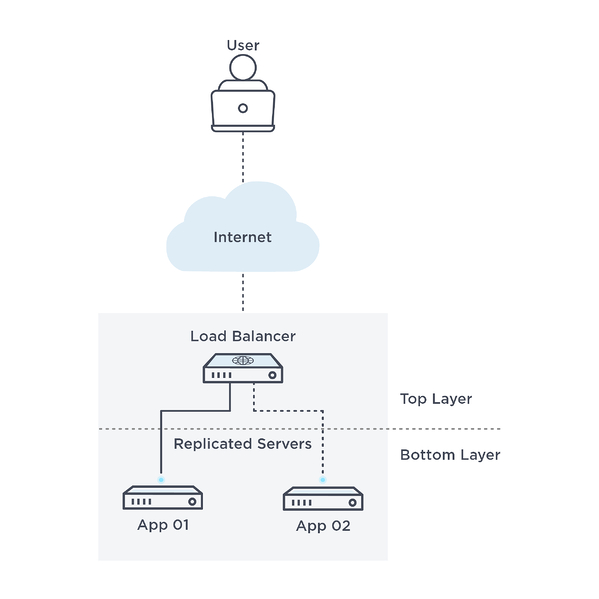
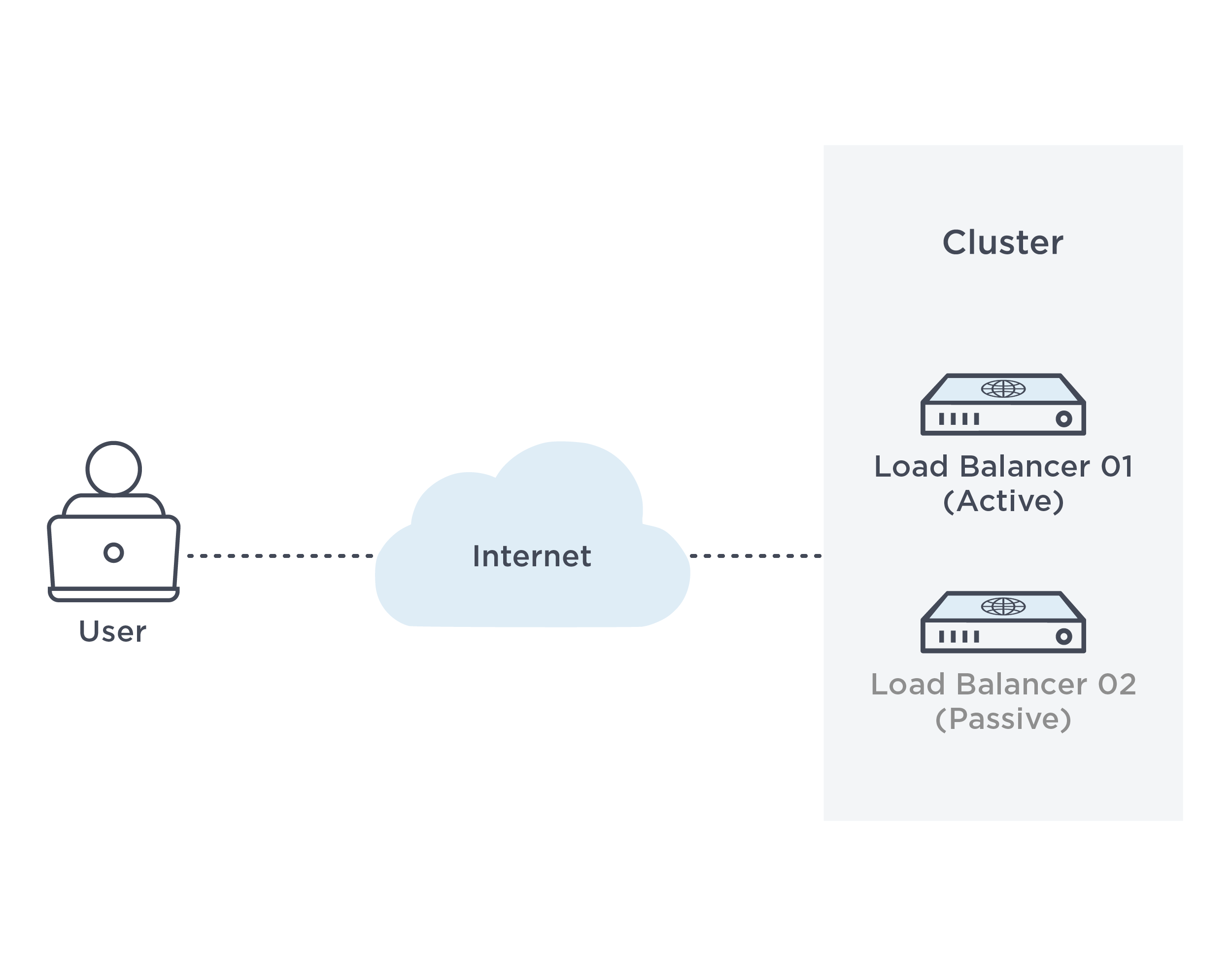
- Clustering—a cluster contains several nodes that serve a similar purpose, and users typically access and view the entire cluster as one unit. Each node in the cluster can potentially failover to another node if failure occurs. By setting up replication within the cluster, you can create redundancy between cluster nodes.
A 5-Step Azure High Availability Checklist
Microsoft Azure provides a variety of tools and mechanisms that can help you achieve reliability. These include published SLAs for Azure services, replication and disaster recovery mechanisms such as Azure Backup and Azure Site Recovery, health probes and check functions to obtain data about the status of operational systems, and more.
Below is a quick checklist that can help you get your requirements and architecture in place while using the relevant Azure capabilities to support your high availability strategy.
1. Define Availability Requirements
Identify the cloud workloads that require high availability and their usage patterns.
Define your availability metricsThese can include:
- Percentage of Uptime
- Mean Time to Recovery (MTTR)
- Mean Time between Failures (MTBR)
- Recovery Time Objective (RTO)
- Recovery Point Objective (RPO)
Use a combination of these variables to define your target Service Level Agreement (SLA) for each application workload.
Consider Microsoft’s SLAs for Azure services
Microsoft defines its own SLA for each Azure service. Consult Azure documentation to see the guaranteed SLA for the services you are using. If you require a higher SLA than that guaranteed by Azure, you can set up redundant components with failover.
2. Plan your High Availability Architecture
Start with a Failure Mode Analysis (FMA)
Identify the types of failure you might experience, the implication of each type of failure, and recovery strategies. Based on your FMA, identify the level of redundancy required for each component. Avoid single points of failure and use load balancing to distribute requests between redundant components.
Consider costs
Remember that each redundant layer effectively doubles your cloud costs (at least for the period the redundant component is active). Ensure you have licenses and infrastructure to support the additional, redundant instances, including storage, networking and bandwidth.
Consider resiliency
Ensure that systems can fail gracefully and restore operations without disruption of service. Isolate critical resources, use compensating transactions and use asynchronous operations to ensure that if a component fails, business operations can continue and be applied to a redundant component.
Replicate data
Ensure application data is replicated in such a way that supports your redundancy strategy and your RTO and RPO. It is not possible to failover or recover if you did not replicate fresh data to the redundant component prior to failure.
Document everything
Document the steps that should take place—whether automatic or manual—to failover to a redundant component and recover or “failback” to the original component. Instructions should be short and clear enough to use in case of emergency.
3. Perform End-to-End Testing
To ensure reliability you should test the system under realistic failure conditions. Use fault injection testing (see an example) to test different failure scenarios, including a combination of failures, and measure recovery time. Test both failover and failback.
Additional tests you can conduct to increase your level of confidence:
- Identify failures under load—perform realistic load testing until a system fails, and observe how failure mechanisms behave.
- Run disaster recovery exercises—conduct a planned or unplanned experiment where systems go down and your team must quickly operate according to your disaster recovery plan.
- Test health probes—the Azure load balancer uses health probes to identify component failure. Test your probes to ensure they respond correctly in case of failure.
- Test monitoring systems—periodically check that data from monitoring systems is accurate, to ensure you can detect failure in time.
4. Deploy Applications Consistently
Any change can result in failure
When you provision Azure VMs or other services, deploy new application code and apply configuration changes, the changes introduced could result in failure. Having an automated, consistent deployment process can minimize the chance of errors and failures, and help you recover more easily.
Consider availability in your release process
Design your release process to enable updates with minimum disruption of service—try to achieve rolling updates that do not require downtime of critical components. You can use blue-green releases or similar strategies to have several versions of your production environment available simultaneously and switch between them to move to a new version.
Plan for rollback
Design a rollback process that can help you automatically restore systems to a previous working version. Deployments should be automated to allow you to spin up a complete environment representing your “last known good” configuration.
5. Monitor Application Health
Use probes and check functions to detect failure in time5. Monitor Application Health
Detecting failures in time is critical to high availability. Implement Azure health probes and use check functions to get fresh data about service availability. You should always aim to run check functions from outside an application.
Watch degrading health metrics
Don’t only pay attention to complete failure. Degrading health metrics can provide a warning signal that failure is about to happen. Create an early warning system by identifying key indicators of application health and alerting operators when a system reaches a problematic threshold value.
Leverage logging and auditing
Leverage Azure’s extensive logging and auditing capabilities: use semantic and asynchronous logging, separate application logs from audit logs and measure remote call statistics such as latency, throughput and percentage of errors.
Watch subscription limits
If you go over the allowed limits of one of your Azure services, you may experience failures. Ensure you are aware of the storage, compute, throughput and other limitations of each Azure service you use, monitor for the limited metrics and act before you go into overage.
Achieve Azure High Availability with Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, cloud automation, Kubernetes integration, and more.
In particular, with Cloud Volumes ONTAP high availability configuration you can ensure business continuity with no data loss (RPO=0) and minimal recovery times (RTO < 60 secs).
Learn more about Azure high availability:
Azure availability zones
Azure Availability Zones allow you to deploy applications across multiple data centers, protecting applications against outages in any one Azure data center. Azure offers several options for high availability, from availability sets that operate locally within an AZ, to region pairs which run applications across different geographical regions. Azure supports high availability for most of its services including Azure VMs, SQL Database and Azure Load Balancer.
To learn more about Azure high availability zones and how to use them for your applications, read Azure Availability Zones: An In-Depth Look.
Azure high availability with Cloud Volumes ONTAP
You can achieve high availability with native Azure tools and services such as Azure Backup, Azure Site Recovery, and Azure High Availability zones. Cloud Volumes ONTAP leverages native Azure Storage capabilities like snapshots, disaster recovery, encryption, and low-RPO HA configuration. Cloud Volumes ONTAP can help you achieve an RPO of zero, with RTO of under 60 seconds.
Read Azure High Availability with Cloud Volumes ONTAP to learn more.
Azure Proximity Placement Groups and Cloud Volumes ONTAP
Azure proximity placement groups are a new service offered by Azure to limit the effects of latency in mission-critical, latency-sensitive workloads. Proximity placement groups allow users to decide where the compute resources they deploy in Azure are placed within an Azure region, making it possible to locate them all within the same data center and therefore cutting down the associated network latencies.
This post goes in detail about how Azure proximity placement groups work and the advantages they provide when combined with Cloud Volumes ONTAP high availability deployments in Azure.
Read more in Azure Proximity Placement Groups and Cloud Volumes ONTAP.
Azure Resiliency Capabilities: A Deep Dive
Azure users have a wide range of out-of-the-box resiliency options for Azure storage. In this post we’ll take a deep dive into all of the resilience options, which use cases they best suit, and what users can do if they need a higher level of resilience than Azure provides.
Read more in Azure Resiliency Capabilities: A Deep Dive.
Cross-Zone High Availability with Cloud Volumes ONTAP for Azure
There’s a better way to protect your data against service disruptions in Azure that go beyond the native Azure resiliency features: Cloud Volumes ONTAP can now leverage Azure zone-redundant storage (ZRS) to gain cross-zone high availability.
Read more in Cross-Zone High Availability with Cloud Volumes ONTAP for Azure
See Additional Guides on Key FinOps Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of FinOps.
AWS Cost Optimization
Authored by Spot
- AWS Cost Optimization Tools and Tips: Ultimate Guide
- AWS Pricing Calculator: Calculate AWS Cost Like the Pros
- AWS Cost Management: Free Tools and 7 Best Practices
Azure Cost Optimization
Authored by Spot
- Azure Cost Management: 4 Ways to Optimize Azure Costs
- Azure Cost Calculator: Estimate Azure Costs
- Azure Cost Analysis: Analyzing Azure Costs, Step by Step
Azure Pricing
Authored by Spot
