Share
Elasticsearch is a distributed database using a clustered architecture. It can be complex to deploy and manage Elasticsearch directly on hardware resources. Kubernetes, the world’s most popular container orchestrator, makes it easier to deploy, scale, and manage Elasticsearch clusters at a large scale.
There are two main options for running Elasticsearch on Kubernetes:
- Deploying Elasticsearch manually using Kubernetes StatefulSets with Persistent Volumes (for stateful components) and Deployments (for stateless components).
- Deploying Elasticsearch automatically using the official Elasticsearch Kubernetes operator—as part of a solution called Elasticsearch Cloud on Kubernetes (ECK).
In this article, you will learn:
- Is Kubernetes a Good Choice for Elasticsearch?
- Manual Deployment of Elasticsearch on Kubernetes
- Automated Deployment of Elasticsearch on Kubernetes with the Elasticsearch Operator
- Best Practices for Running ElasticSearch on Kubernetes
- Elasticsearch on Kubernetes with NetApp Cloud Volumes ONTAP
Is Kubernetes a Good Choice for Elasticsearch?
Elasticsearch is often used for storing and searching through massive amounts of textual data. The Elasticsearch architecture is designed for distributed data. It consists of a cluster, which houses one or more nodes.
Each node performs different functions within the cluster. For example, a master node can control the Elasticsearch cluster, while a data node contains the index and data, and a client node works as a load balancer.
Since a node is an Elasticsearch instance, you can run multiple nodes on one machine. Traditionally, Elasticsearch nodes run on virtual machines (VMs). However, managing this operation can quickly become complex. Instead of using VMs, you can use Kubernetes.
Kubernetes for stateful workloads
Initially, Kubernetes was designed to run stateless workloads. Databases and search engines are often stateful in nature. However, Kubernetes has evolved over the years and now offer features that make it possible to run persistent and stateful workloads with Kubernetes.
PersistentVolumes (PVs) can help you introduce persistent storage into the process, and a StatefulSet is a Kubernetes controller that can help you introduce statefulness into deployments and management.
Kubernetes benefits for Elasticsearch
Once you start running Elasticsearch clusters on Kubernetes, you can simplify the overall process of configuring, managing, and scaling Elasticsearch clusters. You can then easily deploy Elasticsearch on multiple cloud environments and on-premises, using the various automation features available on Kubernetes.
Related content: read our guide to Elasticsearch architecture
Manual Deployment of Elasticsearch on Kubernetes
Elasticsearch is designed for cluster deployment. However, while Elasticsearch uses terms like cluster and node, which are also used in Kubernetes, their meaning is slightly different.
In Elasticsearch, deployment is in clusters. Each cluster contains one or more nodes. A node is an Elasticsearch instance. An Elasticsearch node can control the cluster, store data, or route traffic.
In Kubernetes, deployment is in clusters. Each cluster uses nodes to run workloads. A Kubernetes node is a physical or virtual machine that hosts pods. A Kubernetes pod contains the application data.
Related content: read our guides to Introduction to Kubernetes, and to Managing Stateful Applications in Kubernetes
Understanding the Difference between Elasticsearch and Kubernetes Nodes
A Kubernetes node performs a similar role to Elasticsearch nodes. Except that in Kubernetes the control plane is the one controlling the pods and in Elasticsearch the master node performs this function.
It is critical to understand the differences between Elasticsearch nodes and Kubernetes nodes and configure each properly.
There are several types of Elasticsearch nodes, and each performs a different role. Here are the three types of Elasticsearch nodes:
- Master—nodes that manage the cluster, indices, and choosing new master nodes as needed.
- Data—nodes used to store data.
- Client—also known as the coordinator, this node is responsible for routing traffic.
How to Set Up Roles for Elasticsearch Nodes
To ensure proper performance, you need to set up a minimum of three master-eligible nodes. These nodes should be ready to replace a master node when needed. Here is how you can set this up:
roles:
master: "true"
ingest: "false"
data: "false"
You should also set up at least two data nodes, which are used to persist data, index requests, and receive queries. Here is how you can set this up:
roles:
master: "false"
ingest: "false"
data: "true"
You need to set up two client nodes, which serve as HTTP proxies. Client nodes are exposed to data consumers. If you do not set up client nodes, your data nodes will be used for this purpose and will become exposed to consumers. Here is how to set up a client node: roles:
master: "false"
ingest: "false"
data: "false"
This setup should be enough to get your Elasticsearch cluster up and running. You can easily scale up when needed later on.
How to Set Up Elasticsearch Nodes on Kubernetes
In Kubernetes, you should deploy Elasticsearch data nodes as StatefulSets with PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs). These configurations will ensure that data will persist between restarts.
You can deploy Elasticsearch master nodes as Kubernetes Deployments or StatefulSets. If you decide to use StatefulSets, note that it comes with a headless service per StatefulSet, generated for inter-cluster discovery.
Because Elasticsearch client nodes are stateless, you can deploy them as Kubernetes Deployments. The Kubernetes LoadBalancer Service will be used to forward incoming traffic to Elasticsearch client nodes. The LoadBalancer configures all applications, including Kibana.
Related content: read our guides to Kubernetes Persistent Volumes and Claims
Automated Deployment of Elasticsearch on Kubernetes with the Elasticsearch Operator
Elasticsearch provides a dedicated solution called Elastic Cloud on Kubernetes (ECK). ECK is built as a Kubernetes operator, and makes it easier to deploy Elasticsearch and Kibana on a Kubernetes cluster.
Beyond deployment, ECK also provides general management capabilities for Kubernetes. It can help with managing multiple Kubernetes clusters, upgrading Kubernetes and the Elastic stack, monitoring clusters, cluster capacity expansion and reduction, cluster configuration changes, backups, and dynamically expanding local storage (including Elastic Local Volume).
How to Deploy ECK in your Kubernetes Cluster
Start by installing the custom resource definitions and the Kubernetes operator with corresponding RBAC rules: kubectl apply -f https://download.elastic.co/downloads/eck/1.5.0/all-in-one.yaml
Monitor the logs of the ECK operator using the following command kubectl -n elastic-system logs -f statefulset.apps/elastic-operator
How to Deploy an Elasticsearch Cluster
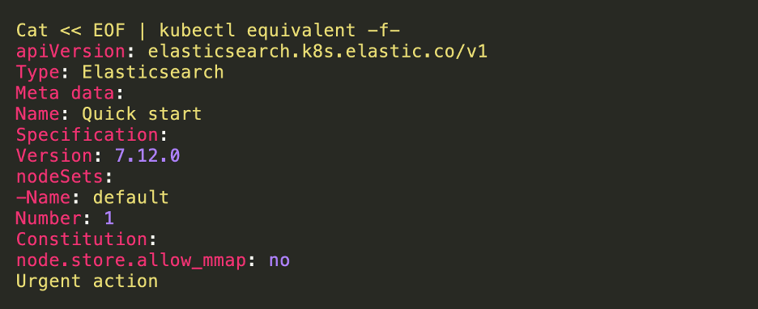
You can use the following YAML configuration to create a simple Elasticsearch cluster. The code below is taken from ECK quick start guide.
You can see cluster creation progress by running the following command (shown with input below): <kubectl get pods --selector='elasticsearch.k8s.elastic.co/cluster-name=quickstart'
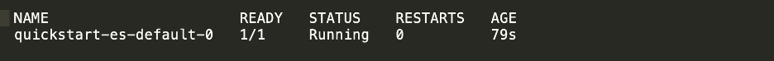
ECK creates a ClusterIP Service that lets you request access to your Elasticsearch cluster in Kubernetes. Use the following command to see available ClusterIP services. kubectl get service quickstart-es-http

You can then request the Elasticsearch endpoint and obtain your password from within the Kubernetes cluster (see the quick start guide linked above for more details).
Best Practices for Running Elasticsearch on Kubernetes
Here are several best practices that can help you successfully run Elasticsearch on Kubernetes:
- Properly configure worker nodes—Elasticsearch requires a lot of memory to sort and aggregate data. To ensure Elasticsearch has enough resources, you should configure worker nodes with the required memory and label the nodes for this purpose.
- Design reliable data management and container storage—Elasticsearch performs a lot of write operations. To meet these requirements, you need to set up a flexible storage and data management layer. You can do this by defining profiles for Elasticsearch and enforcing storage pools with SSDs.
- Implement data security controls—Elasticsearch comes with built-in security capabilities, including role-based access control (RBAC), data encryption, and auditing. In addition to managing access and encryption, you should also backup your data.
Elasticsearch on Kubernetes with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
In particular, Cloud Volumes ONTAP provides Kubernetes integration for persistent storage requirements of containerized workloads.
In addition, Cloud Volumes ONTAP provides storage efficiency features, including thin provisioning, data compression, and deduplication, reducing the storage footprint and costs by up to 70%.
Learn more about optimizing Elasticsearch deployment with NetApp in our free eBook Optimize Elasticsearch Performance and Costs with Cloud Volumes ONTAP.

