Share
What is Elasticsearch on AWS?
Elasticsearch is a popular open-source NoSQL database. Amazon’s managed Elasticsearch Service (Amazon ES) simplifies its deployment, scaling, and operation of clusters in the Amazon Web Service (AWS) cloud environment. The service runs the same code and APIs as on-premises Elasticsearch, ensuring that existing applications are fully compatible.
Amazon ES launches Elasticsearch clusters, provisions resources as needed, and continues to monitor for failed Elasticsearch nodes—automatically replacing them. It thereby enables real-time application monitoring, clickstream analysis, and log analytics.
You can create an Amazon Elasticsearch domain (the Amazon term for an Elasticsearch cluster) through the Amazon console, CLI, or Amazon SDKs.
In this article, you will learn:
- Amazon Elasticsearch Features
- Creating Your First Amazon Elasticsearch Service Domain
- How to Get Data into Amazon Elasticsearch Service
- How to Search with Amazon Elasticsearch Service
- Elasticsearch on AWS Q&A
- Elasticsearch on AWS with NetApp
Amazon Elasticsearch Features
Amazon ES features include:
- Event monitoring and alerting—Amazon ES monitors cluster-stored data and sends notifications and alerts, based on pre-configured thresholds. You can configure alerts using the Kibana interface or the REST API, and can receive notifications through either custom webhooks, Amazon’s simple notification service (SNS), Amazon Chime or Slack. You can also use CloudWatch to monitor instance metrics like CPU, memory, and disk utilization, as well as cluster-level metrics.
- SQL queries—you can query Elasticsearch clusters using SQL syntax, with over 40 SQL functions, commands, and data types. A JDBC driver lets you connect ETL tools to existing SQL-based business data.
- Open-source tool integration—Amazon ES has a built-in integration with Kibana and Logstash. It also lets you trace data analysis using the OpenTelemetry standard. You can use existing code to directly access Elasticsearch tools, including Phonetic Analysis, Ingest User Agent Processor, etc.
Related content: read our guide to Elasticsearch architecture
Creating Your First Amazon Elasticsearch Service Domain
Let’s see how to start a new Amazon Elasticsearch Service (Amazon ES) domain, which represents a hosted Elasticsearch cluster with its settings and resources.
To create an Amazon ES domain using the Amazon console:
- Access the Amazon Console and log in.
- In the Analytics section, select Elasticsearch Service.
- Click Create new domain, and under Deployment Type, select one of these options:
- Production—achieves AWS high availability by deploying across multiple availability zones (AZ) with dedicated master nodes
- Development and testing—deployed on a single AZ
- Custom—lets you select your own configuration options
- Type an Elasticsearch domain name—the name of your cluster.
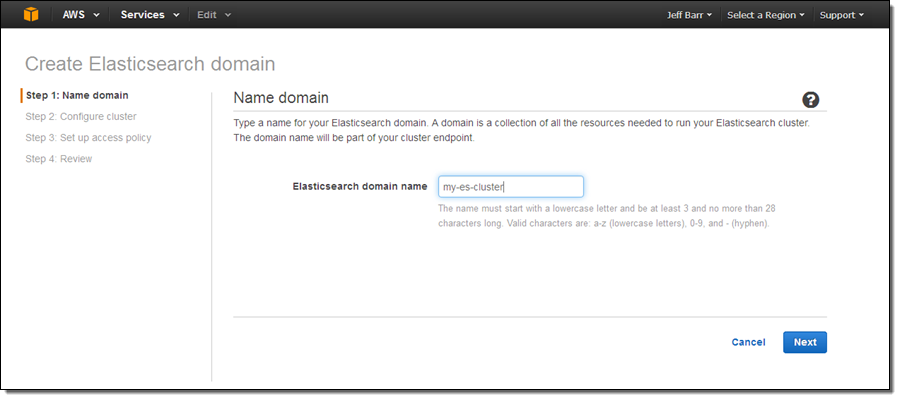 Source: Amazon
Source: Amazon
5. Under Availability Zones, select the number of AWS Availability Zones you want the cluster to run in, between 1-3. Deploying on two or three AZs increases availability, but will also increase your costs because you are running redundant compute and storage resources.
6. Under Instance Type, select the Amazon EC2 instance type for data nodes.
7. Under Number of nodes, select the number of data nodes in your cluster. Each will run on its own EC2 instance.
a. Under Data nodes storage, select Instance, meaning data will be stored in local, non-durable storage on the instance, or EBS, meaning data will be stored in an Amazon EBS volume.
8. Under Network configuration section, select whether you want to enable only VPC access to your instances, or Public access over the Internet.
9. Under Fine-grained access control, to control authorization for your Elasticsearch cluster using Amazon Identity and Access Management (IAM), select Set IAM role as master user. Otherwise, to use the Elasticsearch user database, select Create a master user.
10. Verify the domain configuration, then select Confirm to deploy.
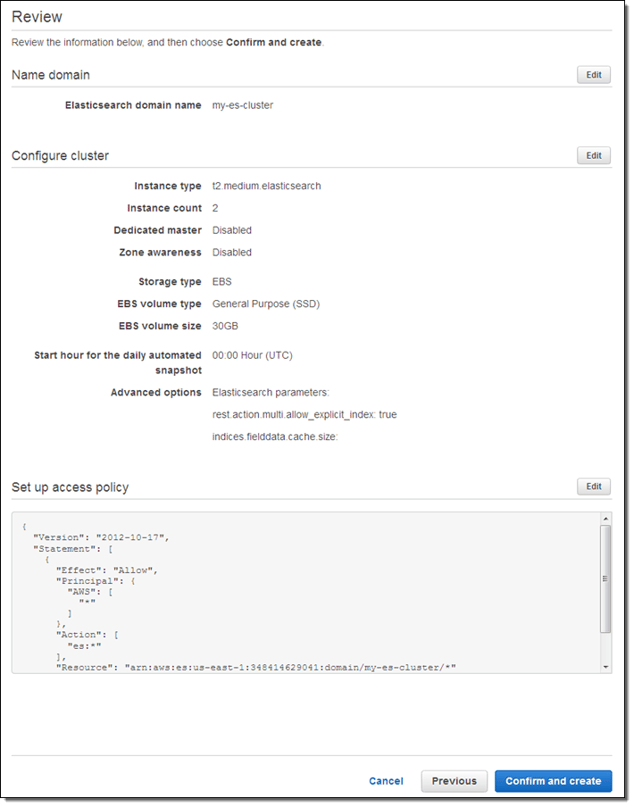 Source: Amazon
Source: Amazon
Related content: read our guide to Elasticsearch in Production on AWS
How to Get Data into Amazon Elasticsearch Service
In Elasticsearch, you feed data into the index in JSON format. In Amazon ES, you don’t need to manually create an index, because the service creates an index when you add your first document.
To create a new document and index it, use an HTTP console such as the Kibana dev console, to make an HTTP call like the following. Remember that if you use another HTTP console, you will need to provide a full URL and credentials.
PUT /customers/_doc/1
{
"firstname":"John",
"lastname":"Smith"
}
This command prompts the service endpoint to automatically create an index named customers, and add a single document into it, with an ID of 1. The string _doc is the Elasticsearch mapping type—if you are using Elasticsearch 7 and up, it is not required.
To add documents in bulk, use a call like the following. A bulk call bundles multiple calls, each of which can perform a different operation on a different index. For example:

How to Search with Amazon Elasticsearch Service
You can perform a basic search using a query like the following:GET /customers/_search?q=name:l*
This returns the first customer document we created in the previous section.
To perform more advanced searches, use a more complex query using the Elasticsearch domain specific language (DSL). Departing from the simple customer data examples above, here is a more complex query provided in the Amazon ES documentation: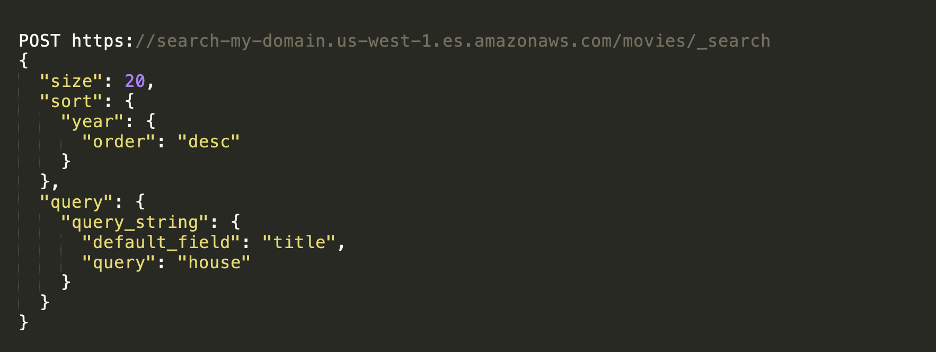
Elasticsearch on AWS Q&A
What Does Amazon Elasticsearch Service Manage on My Behalf?
The Amazon Elasticsearch service manages setup of an Elasticsearch domain (cluster), including infrastructure provisioning within the network environment and installing Elasticsearch software.
After setup, the service performs automated backups, instance monitoring, software patching, and other administrative tasks for as long as the domain runs. You can specify storage settings and select EC2 instances to run your cluster on, in accordance with application requirements.
Does Amazon Elasticsearch Support the Open Source Elasticsearch APIs?
Yes. The code, applications, and tools you currently use with Elasticsearch will work seamlessly with Amazon’s Elasticsearch Service. See the official list of Elasticsearch supported operations.
How Can You Migrate Data from An Existing Elasticsearch Cluster to a New Amazon Elasticsearch Domain?
Migrating data from one Elasticsearch cluster to other entails creating a snapshot of the existing cluster and storing it in an Amazon S3 bucket. After creating a new domain, you can use the Elasticsearch restore API to load data into it from the snapshot.
Elasticsearch on AWS with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
Cloud Volumes ONTAP supports advanced features for managing SAN storage in the cloud, catering for NoSQL database systems, as well as NFS shares that can be accessed directly from cloud big data analytics clusters.
In addition, Cloud Volumes ONTAP provides storage efficiency features, including thin provisioning, data compression, and deduplication, reducing the storage footprint and costs by up to 70%.
For more on optimizing Elasticsearch deployment with NetApp, download our free eBook Optimize Elasticsearch Performance and Costs with Cloud Volumes ONTAP today.

