Share
Many companies are migrating workloads and data to the cloud in order to leverage the cloud’s flexibility and scalability but is there a clear-cut guideline for when to use object storage vs. block storage in the cloud, like AWS EBS?
What are the specific benefits and drawbacks of using either in the cloud?
AWS, the leader of the cloud market, kicked off its cloud domination with its cloud object storage offering Amazon S3. Block storage on AWS is available in the various types of Amazon Elastic Block Store (Amazon EBS) volumes.
In this article, we'll take a look at block storage vs. object storage, help you learn about the block and object storage options available on AWS and show how NetApp’s cloud solutions can add even more value and flexibility to your AWS deployment.
About Storage Systems
Object Storage Systems
Enterprises use object storage for a number of different use cases, such as static content storage and distribution, backup and archiving, and disaster recovery. Object storage works very well for unstructured data sets where data is mostly read (rather than written to). It’s more of a write once, read many times use case.
Normally, each object has three major components: the data or content of the object, a unique identifier associated with the object, and metadata. The unique identifier allows developers to easily track and maintain the object details. Additionally, each object has metadata, containing contextual information about data such as its name, size, content-type, security attributes, and URL. This metadata is generally stored as a key-value pair.
For object-based storage systems, there is no hierarchy of relations between files. Two related files are not necessarily stored on the same physical medium, such as a storage node or the same disk, and the hierarchy is flat. Even though the files are not stored “together” the relationship between them can be maintained by the storage application developers.
This kind of approach provides a lot of flexibility in designing systems where files are generated and can be accessed by multiple content producers and consumers.
Block Storage Systems
Block storage systems are used to host databases, support random read/write operations, and keep system files of the running virtual machines. Data is stored in volumes and blocks where files are split into evenly-sized blocks. Each block has its own address, but unlike objects they do not have metadata. When storing large amounts of data, files are split into smaller chunks of a fixed size, the “blocks,” which are distributed amongst the storage nodes. This also supports the volume IO performance.
Public cloud providers allow creating various file systems on their block storage systems to enable their users to store persistent data like a database. In addition, an Amazon EBS volume is accessed from an Amazon EC2 instance over an AWS dedicated or shared network. Another advantage of using block storage in the cloud is its backup mechanism. For example, AWS EBS offers a snapshot feature that is essentially an incremental point in time backup of your volume. You can also automate this block-based backup capability for DR purposes.
Now that we’ve gone through an overview of block and object-based storage systems, let’s look at the fundamental differences between block storage vs. object storage.
Why Object-based Storage and Not Block?
The primary advantage of the object-based storage is that you can easily distribute objects across various nodes on the storage back end. As each object is referred to and accessed by its unique ID, an object can be located on any machine in the data center. With block storage, file distribution becomes complex, even across multiple servers. This results in inefficient utilization of resources when compared to object-based storage.
Versioning on the file level using cloud object storage is much simpler than managing the backup of blocks or entire volumes. Each object can be independently versioned and maintained across multiple locations. In order to provide reliability, most cloud service providers use techniques such as storing copies of object across their storage nodes and multiple regions.
The object store allows you flexibility in terms of file organization, as inherently it is unstructured. It is more ideal for data that requires high-read frequency. Plus, the object storage model allows you to search through the metadata a great deal faster than compared to the block-based approach. A good use case to exemplify that is big data analytics: When dealing with increasingly large number of files, the object storage method of indexing the data and location (the metadata), and thus fixes the main problem connected with big data, which is scalability.
Why Block-based Storage and Not Object?
With block-based storage, it is easier to modify files because you have access to the specific required blocks in the volumes. In object-based storage, modifying a file means that you have to upload a new revision of the entire file. This can significantly impact performance if modifications are frequent.
One more area where the block storage wins is the IO speed. While access to an object generally relies on HTTP protocol, block storage systems are mounted as a storage device on the server with underlying file system protocol (such as NFS, CIFS, ext3/ext4 and others) designed specifically for file operations. Object-based mechanisms should not be used for high-activity IO operations such as caching, database operations, log files, etc. Block storage mechanisms are better suited for these activities.
The following diagram summarizes the differences:
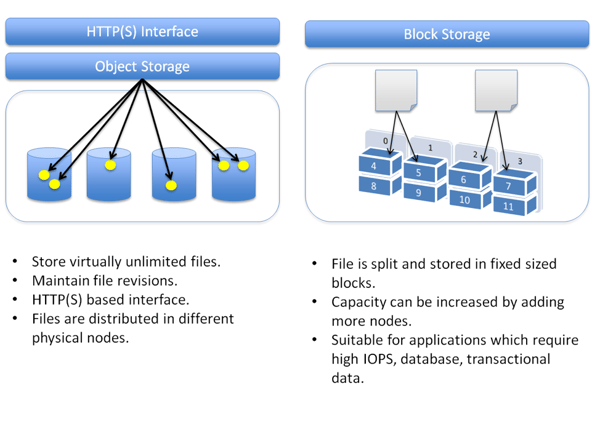
Amazon EBS vs. Amazon S3
Amazon EBS is the AWS block storage offering and Amazon S3 is the AWS object storage offering. So the question is: Amazon EBS or Amazon S3?
You might want to consider the following key differences when making a decision for your cloud storage systems:
- Access: Amazon EBS can be accessed with an Amazon EC2 instances only, while Amazon S3 can be accessed over the Internet directly. You can use file system applications such as S3fs or goofys, which allow you to mount an Amazon S3 bucket; however, because they’re not native options, they have some limitations (such as the file size when using S3fs).
- Scale: Scaling cloud block storage generally involves setting up a distributed file system or a RAID of multiple volumes. Amazon EBS offers Amazon EBS volumes of up to 16 TB in size, and you can RAID a few volumes together to suit your needs. Still, this is a complicated process compared to the way object-based storage works. In comparison, one Amazon S3 object can be 5 TB and you can store unlimited objects of 5 TB in Amazon S3.
- Speed: The IO is a good deal faster on Amazon EBS than on Amazon S3, because Amazon EBS is attached to the Amazon EC2 instance as a file system and relies on NAS protocol. It supports various volume types (gp2,io1, st1, and sc1, each for a different budget and need) that can help achieve increase IO performance with guaranteed IOPS based on SSD, such as PIOPS and General Purpose.
- Versioning: With Amazon S3, the Amazon object storage service, maintaining multiple versions/revisions of objects stored in file is a lot simpler and cost-effective as compared to Amazon EBS, where you have to make a snapshot of entire disk.
- Price: Amazon S3 is significantly cheaper than Amazon EBS. For example, storing 100 GB of data on Amazon S3 will cost around $3, as compared to around $10 a month on general purpose SSD Amazon EBS.
Object Storage Vs. Block Storage with NetApp Cloud Solutions
Whether you’re using block or object storage in the cloud, NetApp cloud solutions can provide added benefits for your AWS deployments in either format.
Cloud Volumes ONTAP (formerly ONTAP Cloud) for AWS allows users to leverage both block and object storage through the use of data tiering between Amazon EBS and Amazon S3. By tiering data to Amazon S3 from Amazon EBS, you get an inexpensive way to store infrequently-used data in a cold tier that can be easily brought back up to the hot tier for active use when immediate use is required. And with data deduplication, data compression, thin provisioning, and zero-capacity FlexClone writable copies, Cloud Volumes ONTAP significantly lowers the amount of space consumed for storage, lowering your overall AWS storage costs no matter if the format is cloud block storage or cloud object storage. Plus, those Cloud Volumes ONTAP storage efficiencies not only work with AWS storage but also with and with Azure storage.
NetApp also offers Cloud Sync, a data migration, data synchronization, and data transfer tool that can move file and object storage file systems to and from NFS, CIFS, Amazon S3, Azure Blob storage, NetApp StorageGRID® Webscale appliances, or any other object-format storage system.
Conclusion
So who comes out on top in this object storage vs. block storage matchup? Based on this discussion of the pros and cons of using a object-based storage model vs. a block storage system, we can say that when designing systems that expect a huge amount of files from users, object-based storage is the better alternative. As a use case, object-based storage is useful when you want to write once and access from anywhere. Block storage, on the other hand, is useful for File IO or persistent storage, such as databases.
Where access speed is critical and frequent modifications are performed on files, choosing a storage back end with block storage will simplify implementation and support performance required. In terms of cost effectiveness, object stores such as Amazon S3 are typically significantly more affordable than file-based storage platforms such as Amazon EFS.
With NetApp, block storage and object storage don’t have to be mutually exclusive. NetApp cloud solutions offer a number of ways to take advantage of the more inexpensive storage in object format, without losing the efficiency of block storage. It's block storage vs. object storage without any losers. Mainly this comes in the form of automatic data tiering. You can leverage the attractive pricing of Amazon S3, block storage performance on Amazon EBS disks when you need it, and none of the hassle of tiering manually.

