Share
A Kubernetes ecosystem contains various built-in workload resources to manage the various pods where the actual workloads are run. Kubernetes utilizes workload resources and provides mechanisms for scaling pods to match workloads with changing resource requirements. Scaling resources or a cluster’s node pools dynamically is a powerful mechanism offered by Kubernetes that facilitates both cost optimization and enhanced performance.
In this article, we discuss how Kubernetes handles autoscaling, various options for manual scaling, and the best practices for optimal scaling to prevent service disruption.
The topics we’ll cover in this article include:
- How Kubernetes Enables Scaling
- Declarative Scalability Using Kubernetes Scaling Policies
- Best Practices for Scaling Kubernetes Workloads
How Kubernetes Enables Scaling
For applications that leverage a microservice architecture, it’s possible to scale each service independently for granular control of workload performance. In Kubernetes clusters that are autoscaled, node pools are dynamically managed through node auto-provisioning. Though Kubernetes supports a number of native capacity-scaling approaches, it’s often complex to assess when and what to scale.
Types of Auto Scaling in Kubernetes
By default, Kubernetes supports three types of autoscaling:
Horizontal Scaling (Scaling Out)
Horizontal scaling involves altering the number of pods available to the cluster to suit sudden changes in workload demands. As the scaling technique involves scaling pods instead of resources, it’s commonly a preferred approach to avoid resource deficits.
Vertical Scaling (Scaling Up)
Contrary to horizontal scaling, a vertical scaling mechanism involves the dynamic provisioning of attributed resources such as RAM or CPU of cluster nodes to match application requirements. This is essentially achieved by tweaking the pod resource request parameters based on workload consumption metrics.
The scaling technique automatically adjusts the pod resources based on the usage over time, thereby minimizing resource wastage and facilitating optimum cluster resource utilization. This can be considered an advantage when comparing Kubernetes horizontal vs. vertical scaling.
Cluster/Multidimensional Scaling
Cluster scaling involves increasing or reducing the number of nodes in the cluster based on node utilization metrics and the existence of pending pods. The cluster autoscaling object typically interfaces with the chosen cloud provider so that it can request and deallocate nodes seamlessly as needed.
Multidimensional scaling also allows a combination of both horizontal and vertical scaling for different resources at any given time. While doing so, the multidimensional autoscaler ensures there are no idle nodes for an extended duration and each pod in the cluster is precisely scheduled.
Options for Manual Kubernetes Scaling
Kubernetes offers various options to manually control the scaling of cluster resources. These include:
The “kubectl scale” command
To instantly change the number of replicas, administrators can use the kubectl scale command to alter the size of a job, deployment, or replication controller. This command uses syntax of the following form:
$ kubectl scale --replicas=desired_replica_count object_type/object_nameFor instance, to scale a deployment named darwin to three replicas, the command should be:
$ kubectl scale --replicas=3 deployment/darwinDeclarative Scalability Using Kubernetes Scaling Policies
Kubernetes allows for the declarative creation of pod autoscalers to manage Kubernetes scaling requirements. When scaling up or down you can set the highest rate of change by specifying a policy within the behavior section of the autoscaler’s specifications.
The sample snippet below shows the scaling policy defining scaling down behavior:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60The periodSeconds spec defines the time for which the policy remains valid. The upper policy value allows the scaling down of at most four replicas in a minute. The lower policy value specifies that at most 10% of existing replicas can be scaled down in a minute.
Kubernetes Automatic Scaling with the Horizontal Pod Autoscaler (HPA) Object
The Kubernetes HorizontalPodAutoscaler object updates pods, deployments and statefulsets to match demands by automatically scaling workloads. The HPA’s response to increased load is to dynamically provision additional pods. In case of a decrease in load and the number of pods is above the specified minimum, HPA instructs workloads when it is time to scale down the workload resource.
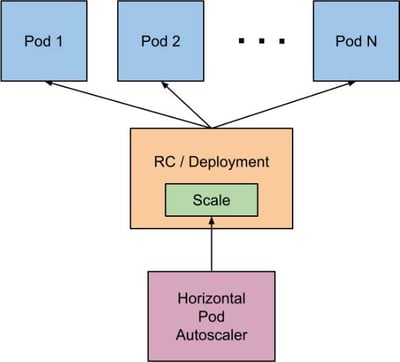
The Kubernetes HPA Object
Pod autoscaling is implemented as a controlled loop that is run at specified intervals. By default, Kubernetes runs this loop every fifteen seconds, however, the interval can be configured by specifying the --horizontal-pod-autoscaler-sync-period parameter of the kube-controller-manager.
How Does HPA Work?
Cluster administrators typically deploy the HPA object either using the kubectl autoscale command with arguments or as a HorizontalPodAutoscaler object. The code shown below gives a sample declarative configuration for the HPA object:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50Kubernetes allows the implementation of HPA both as a controller and an API resource. The controller runs within the control plane, and periodically adjusts the scale of the target object (deployment, ReplicaSet, replica controller) to match resource metrics. On each testing instance, the controller obtains and compares resource utilization metrics against those specified in the declarative configuration file.
The HPA Algorithm
The controller uses a ratio between current and desired metric values to enable scaling. A typical calculation for desired replicas looks similar to:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]This implies that if the current resource metric is 100m and the desired value is 50m, the number of replicas is calculated to be doubled (100/50=2).
Metrics Used by the HPA Object
The HPA object tracks two kinds of metrics:
Resource Metrics
Resource metrics refers to the standard resource management data, such as memory and CPU consumption metrics, provided by the Kubernetes metric server.
Custom Metrics
The HPA metrics interface also accepts custom metrics associated with a Kubernetes object through an API. The custom metrics API allows cluster administrators to install a metrics collector, collect the desired application metrics and expose them to the Kubernetes metrics server. Some commonly used custom metrics for Kubernetes include request throughput, latency, dependencies, and queue depth.
Best Practices for Scaling Kubernetes Workloads
Some of the recommended practices for seamless workload scaling include:
Use an Up-To-Date Version of the Autoscaler Object
Kubernetes is a high-velocity platform with periodic addition of new features and releases. With every new release, performance and compatibility of different Kubernetes versions with the autoscaler releases are thoroughly tested and documented. It’s recommended to use only the compatible autoscaling object of the Kubernetes control plane version to ensure the cluster autoscaler appropriately simulates the Kubernetes scheduler.
Keep Requests Close to the Actual Usage
The cluster autoscaler performs scaling operations depending on node utilization and pending pods. If pod resources are overprovisioned, workloads fail to either consume them efficiently or lead to lower node utilization. As the performance of a cluster’s autoscaler is dependent on the resources provisioned for each pod, it’s crucial to ensure the pod resource requests are comparable to their actual consumption. As a recommended best practice, cluster administrators leverage historical consumption statistics, and ensure each pod is allowed to request resources close to the actual trend of usage.
Node Groups Instances with Similar Capacity
A cluster autoscaler works with the assumption that every node of a node group has the same memory and CPU resource capacity. To achieve this, a template node is created by the autoscaler on which all cluster-wide scaling operations are performed. To ensure the autoscaler’s created template node performs accurately, it’s ideal to have node groups with nodes having the same resource footprint.
Define Resource Requests and Limits for Each Pod
The autoscaler relies on each node utilization and pod scheduling status to tackle scaling changes. Calculating node utilization relies on a simple formula: dividing the sum of all the resources requested by the capacity of the node.
As a result, missing resource requests for one (or many) pod affects calculation of node utilization, thereby leading to suboptimal functioning of the algorithm. It’s a recommended practice to ensure all pods running within a node have resource requests and limits defined for optimal scaling at any given time.
Specify Disruption Budgets for All Pods
Kubernetes supports defining a pod disruption budget as a cluster object for voluntary/involuntary disruption of workload replicas to prevent incurring losses. Cluster administrators should define pod disruption budgets to ensure the autoscaler maintains a minimum threshold of pods for optimum functioning of cluster services while preventing budget overrun.
Summary
Kubernetes offers multiple innate approaches to scale applications by dynamically changing pod replicas. Though this works well for pods, replicasets, deployments and replica controllers, stateful workloads present a challenge since scaling down statefulsets mostly result in orphaned persistent volumes.
NetApp can help you scale your Kubernetes deployments with Cloud Volumes ONTAP. The cloud and hybrid data management platform enables seamless scaling into the petabyte scale, with robust data protection features for Kubernetes deployments in the cloud.
Find out more details on how Cloud Volumes ONTAP helps achieve advanced storage management capabilities for persistent volumes in this selection of success stories adopting Cloud Volumes ONTAP in Kubernetes deployments.

FAQs
How scalable is Kubernetes?
With its recent major release of 1.23, Kubernetes offers built-in features for cluster scalability to support up to 5000 nodes and 150,000 pods. The platform allows multiple auto scaling options based on both resource and custom metrics (for application scaling) and node pools (for comprehensive cluster scaling).
Can Kubernetes scale nodes?
Kubernetes supports auto scaling of both control plane and worker nodes for optimum performance handling. With inherent cluster scaling capabilities, Kubernetes allows increasing or reducing the number of nodes in the cluster based on node utilization metrics and the existence of pending pods. To request or deallocate nodes dynamically, the cluster autoscaling object typically interfaces with the cloud service for handling load spikes.
Can Kubernetes do vertical scaling?
In addition to supporting horizontal scaling to add more pods, Kubernetes also allows vertical scaling that involves the dynamic provisioning of attributed resources, such as RAM or CPU of cluster nodes to match changing application requirements. A vertical scaling is essentially achieved by tweaking the pod resource request parameters based on workload consumption metrics.
