Share
Applications are essential to almost every business today—and when those applications fail, there can be serious impacts on the business. A key part to ensuring applications and the data they run on are always available is a high availability storage design. How can you ensure your Google Cloud storage is highly available?
Configuring a high availability storage design in the cloud can be complex and needs to carefully balance the recovery point objective (RPO) against recovery time objective (RTO). But why not have both a low RTO and an RPO of 0?
That’s what Cloud Volumes ONTAP High Availability (HA) for Google Cloud provides. With this out-of-the-box high availability configuration, all of the difficult design work to provide a solution that ensures access to your data, removing time lost to potential data downtime, but with a simple design, high storage efficiency, and excellent performance.
In this blog post we’ll take a closer look at Cloud Volumes ONTAP’s high availability architecture for Google Cloud, and show how its design utilizes multiple availability zones to provide the best solution for storage high availability in cloud computing.
What Are Highly Available Architectures?
High availability architecture is a design goal. It is a target that you hit by designing out all possible points of failure and scenarios that could cause downtime. Architects must pay attention to every facet of the design, including network, compute, application, storage, and even monitoring and alerting systems, ensuring no single point of failure.
The architecture of your storage should ensure that the RPO is zero; that is to say, in a failure scenario, there will be no data loss. There are many use cases that can benefit from this level of high availability: databases, media production, machine learning, and other production workloads and customer-facing applications are just some examples. Suppose there is a failure around any part of the primary storage system. In that case, the service should failover to a secondary storage system, and the RTO should be so low that the failover is seamless, and negligible to application users.
High availability systems ensure that your application is never down. For an e-commerce site, for example, high availability means that even though the site is experiencing a failure, customers will still be able to place orders instead of looking elsewhere, protecting income and reputation. Or it could be that critical data is always available to employees or third parties using your service, keeping within SLA and meeting any legal regulations that may cover the data, again protecting income and reputation.
Google Cloud Storage High Availability
Google Cloud Platform offers some level of what is generally considered high availability with its Regional Persistent Disks (RPD). RPDs have primary and secondary availability zones within a region, with the disk mounted to a VM in the primary availability zone. During a zone outage, the disk is force mounted to a VM in the secondary zone; the VM could be hot standby or provisioned as part of a DR system. However, RPDs are less performant than Zonal Persistent Disks (ZPDs) with lower maximum sustained read IOPS and lower maximum sustained throughput for read and write.
In both of these cases, hitting the enterprise-standard RPO=0 is going to be unlikely if not impossible. To achieve that level of availability, Google Cloud users can turn to NetApp Cloud Volumes ONTAP.
The Cloud Volumes ONTAP High Availability Solution
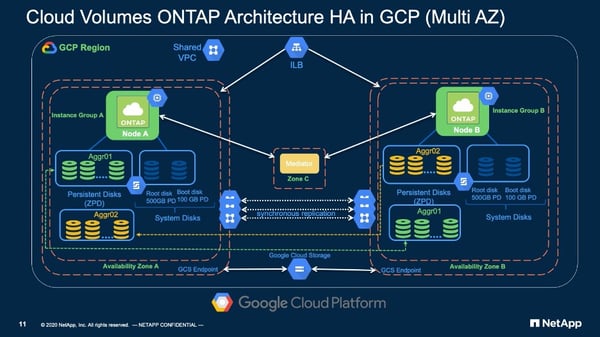
The Cloud Volumes ONTAP HA solution consists of a high availability cluster of two Cloud Volumes ONTAP instance groups and a mediator node, each located in a different availability zone within the same region, sharing a VPC.
Synchronous Mirroring
Each instance group contains a powerful compute node running ONTAP with root and boot system disks and two groups of zonal persistent disks (ZPDs). To explain the two groups of ZPDs, consider instance group A: the first group of ZPDs in instance group A make up the aggregate for the ONTAP node A, and the second group of ZPDs are virtually the aggregate for the ONTAP node B.
All data volumes on instance A Aggr01 are synchronously mirrored to instance B Agg01, and all data volumes on Aggr02 in instance B are synchronously mirrored to Aggr02 in instance A. The synchronous mirrors ensure that all writes to a data volume must be committed to both source and destination data volumes before the write is acknowledged, guaranteeing no data loss. Synchronous mirror data flows over the high bandwidth low latency inter-availability zone links. It also keeps Cloud Volumes ONTAP in control of the data using proven existing synchronous mirror technology.
The Failover Process
The GCP Internal Load Balancer (ILM) manages connectivity to NFS and SMB services and node management services, forwarding traffic destined for a particular IP to the correct ONTAP node. If an instance group becomes unavailable, the partner ONTAP node will take over the second aggregate and provide shared services. The ILM will then forward the inaccessible node's traffic to its partner node, providing continuity of service.
For iSCSI connectivity, multipath I/O and ALUA (Asymmetric Logical Unit Access) manage connectivity. During a zone outage, the partner node takes over the second aggregate, and ALUA ensures connectivity is maintained.
The Failback Process
Once the outage is resolved, and the instance group is again available, the Cloud Volumes ONTAP node must resynchronize HA volumes on its first aggregate with its partner Cloud Volumes ONTAP node’s second aggregate. As soon as the HA volumes are in sync, the synchronous mirror is recreated, and the partner Cloud Volumes ONTAP node will give back the file share services. The ILM will again forward traffic for the particular IP to the Cloud Volumes ONTAP node.
Again, with iSCSI connectivity, the process is slightly different. Once the HA volumes are in sync, the synchronous mirror is recreated, and ALUA tells the client nodes to revert to the Cloud Volumes ONTAP node.
Cloud Volumes ONTAP High Availability Benefits
As we have explained above, Cloud Volumes ONTAP HA for GCP uses a multi-AZ high availability architecture design, which provides a continuation of service to applications during the complete loss of an availability zone. The ILM failover and node take over to yield an RTO to your business of fewer than 60 seconds.
The synchronously mirrored volumes use existing, proven NetApp technology, which ensures no data loss and thus provide an RPO of 0.
The solution comes with the standard Cloud Volumes ONTAP storage efficiency features. These include thin provisioning, data compression, deduplication, and compaction, which reduce cloud storage costs by up to 70%, which reduces I/O to the ZPDs, allowing higher overall throughput.
Automatic storage tiering between Persistent Disk and Cloud Storage provides additional cost savings by moving unused disk data blocks to object storage when not in immediate use, and back up to the performance tier when needed.
Conclusion
The Cloud Volumes ONTAP high availability configuration on Google Cloud Platform provides a ready-to-go, easy-to-provision solution to the problem of storage availability.
Cloud Volumes ONTAP’s HA configuration is a trusted feature that has been ensuring business continuity for workloads in the cloud on AWS and Azure, and on NetApp hardware for years. Now it’s ready for Google Cloud.
A true multi-AZ solution that will keep going after the loss of an entire availability zone, only your storage admins will know something happened.
Watch this webinar Zero Data Loss. Unlimited Uptime to learn more about Cloud Volumes ONTAP high availability in Google Cloud.
Watch this video to learn how to achieve zonal protection for your files and block storage on the Google Cloud Platform.

