Share
Kubernetes, our customers, and us
At NetApp, we don’t have a bit of doubt that containers and Kubernetes are the future of computing for modern cloud-native applications. We also believe that’s true for many of the traditional lights-on applications that our customers run on virtual machines or bare metal platforms today. We view Kubernetes as the next-generation cluster operating system that will run all workloads, both modern and traditional, over time. Our customers are at different phases in the journey of adopting containers and Kubernetes to address their data-driven digital transformation and application modernization initiatives. Such initiatives almost always use one or more of the following methodologies:
- Containerize existing applications as-is (lift and shift, blanket containerization).
- Refactor existing applications as microservices deployed in containers to adapt to a cloud-native paradigm.
- Write new microservice-centric applications deployed in containers with a cloud-first infrastructure consumption target.
As our customers build out their application modernization initiatives using one or more of these methodologies, they are overwhelmingly choosing Kubernetes as the core foundational building block to power such strategies. Consequently, Kubernetes has rapidly gained momentum since its unveiling in 2014. It is now the strategic platform of choice for running next-generation workloads that include CI/CD pipelines, scale-out database clusters, machine learning, financial risk modeling, genome sequencing, oil and gas exploration, and media processing.
We at NetApp have also fully embraced Kubernetes in a multitude of services. We leverage Kubernetes for operating our own fully managed storage offerings in the cloud, like NetApp® Cloud Volumes Service, which uses a highly scalable and reliable Kubernetes-based control and management plane for serving thousands of production customers.
At NetApp, we saw the promise that Kubernetes held for stateful enterprise workloads early on, leading us to invest in, develop, and release NetApp Trident, an open-source, dynamic, external storage orchestrator. Trident enabled our customers to quickly and easily consume persistent storage from NetApp’s broad and proven storage portfolio, both on the premises and in the public clouds. Today, Trident is used by hundreds of customers as a persistent storage provider to back thousands of Kubernetes applications. Trident implements the standard Container Storage Interface (CSI) for accessing persistent storage from Kubernetes pods. It also exposes a select set of highly differentiated NetApp storage and data services like QoS support, which our customers use to back their modern apps.
With the success of Trident in the backdrop, in talking with our customers, we found that they wanted to do a lot more with the data in their Kubernetes applications. Consuming persistent storage with Trident solved the first-order problem of backing stateful applications with reliable and high-performing persistent storage. However, it did not satisfy their appetite for a richer set of data management functionality, which was essential for wide adoption of Kubernetes and containers for running business-critical applications.
Why we built Astra
As customers adopted Kubernetes and containers, they quickly realized that some of the critical data management functionality in their traditional VM-centric IT environments is not readily available in Kubernetes. However, they wanted to address their data protection, disaster recovery, and migration and application portability use cases to run business-critical applications on Kubernetes.
Also, most Kubernetes applications have a fundamentally different architecture that is not like traditional three-tier IT apps. A Kubernetes application can have one or more containers deployed across multiple nodes, which implement a set of microservices with their individual backing datastores. Therefore, data management at the level of a VM (provided that the customer is running Kubernetes on a VM-based platform with worker nodes hosting multiple pods in a VM) is too broad. On the other hand, providing data management at the level of individual containers that comprise a Kubernetes application is too narrow. Most of our customers have more than one environment in which they run Kubernetes clusters. Therefore, they also wanted a consistent set of tools to achieve their data management tasks without needing to use a diverse set of interfaces based on where they are running Kubernetes.
Lack of enterprise-grade persistence and data management services in Kubernetes is also forcing some of our customers to make sub-optimal decisions regarding their stateful Kubernetes workloads. They are working around by doing the following:
- Running their stateful applications outside Kubernetes clusters and managing them separately, while running only stateless applications inside Kubernetes that depend on external services for storing their state and data.
- Using fully managed database-as-a-service offerings in the cloud from their stateless apps running on Kubernetes.
- Using a cloud or on-premise object storage solution to store application state even when it does not make sense do so.
The above approaches are less than ideal for customers who want to build truly portable workloads that seamlessly work across multi-hybrid cloud environments.
Application focus
We built Astra (announced in April 2020) to address our customers’ application-aware data management requirements and address our customers' issues managing their stateful Kubernetes workloads. With the general availability (GA) release of Astra, we offer a fully managed, multi-hybrid cloud application-aware data-management platform. Astra supports a rich set of application-aware data management functionality, is designed to enable seamless application portability, and provides a consistent set of interfaces for managing the data lifecycle of Kubernetes applications.
Astra has focused on the application as the unit for providing data services and management from the outset. This focus is because well-architected Kubernetes applications implement loosely coupled microservices that are deployed in containers. These applications often use multiple backing datastores so that developers have the freedom to choose the datastore that is best suited for the microservice instead of using a single large datastore for the entire application. As a result, providing wholistic data management needs to account for all state, data, and configuration backing the microservices that implement the application instead of individual pods, containers, and storage volumes (PVs).
Astra’s application awareness for a range of popular applications (PGSQL, MySQL, Jenkins, etc.) intelligently identifies application boundaries within namespaces and discovers applications automatically. Snapshot applications (including all of their Kubernetes resources and data volumes) provide local data protection. Backup and restore of full applications across and within clouds enables business continuity after a disaster. And migrating and moving applications use active cloning to re-instantiate applications across clusters and clouds with their state and data intact.
Consistent experience no matter where customers are running Kubernetes
Astra is designed to provide a consistent set of user interfaces (APIs and UIs) that abstract the diversity and complexity of adapting to the rapidly evolving multi-hybrid cloud world in which our customers increasingly find themselves. A broad set of similar but ultimately different toolsets, APIs, and UIs causes friction and inability to deliver much-needed enterprise-grade data management functionality in a cloud-native world across all environments where our customers run Kubernetes. We designed Astra so that our customers don’t have to learn and relearn how to manage Kubernetes in every environment. And they don’t have to develop a patchwork of scripts and admin tools to accomplish these tasks, which do not scale as they scale their Kubernetes deployments.
Simple and fully managed
Our customers who have a cloud-first strategy also drove us to build Astra as a fully managed service operated by NetApp that does not require an expert-level Kubernetes skillset to use. There is no need to set up and provision servers and VMs for running Astra, and no software to download, install, manage, patch, upgrade, and license. Once customers register their Kubernetes clusters, Astra automatically discovers all applications running in the clusters, provisions storage and storage classes using Trident, and displays a rich catalog of data management functionality that can be used with just a few clicks.
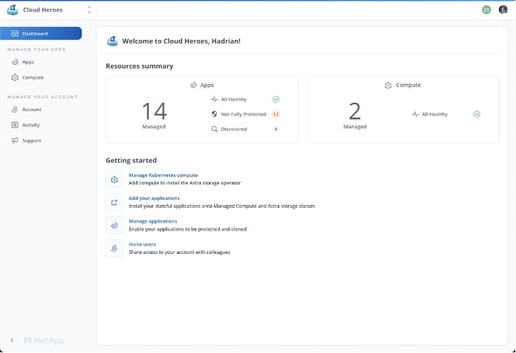
Astra dashboard.
What to expect at GA and in future
Today, we are excited to announce support for Kubernetes applications hosted on Google Kubernetes Engine clusters in Google Cloud using NetApp’s fully managed Cloud Volumes Service (CVS) for Google Cloud as the persistent storage provider. Stay tuned for Kubernetes support in other major public clouds and on-premises. We will also support a wide variety of persistent storage providers, application-awareness for popular cloud-native applications, and enhanced data management functionality.