Share
High-performance computing (HPC) drives the frontiers of science, finance, engineering, education, chemistry and genomics, and a host of other compute-intensive industry verticals. HPC workloads are mission-critical for most enterprises and feature prominently in discussions over enterprise cloud migration. The flexibility and heterogeneity of HPC cloud services provide a welcome contrast to the constraints of on-premises HPC.
In this blog, we’ll take a closer look at how one company solved their HPC workload problems in Cloud Volumes Service for AWS. With Cloud Volumes Service, they were able to complete full runs of big data analysis, which always timed out, in just a few hours. Finally, we’ll unveil a reference architecture for HPC workloads on Cloud Volumes Service for AWS, to give you a precise schematic of its fit and function for HPC on AWS.
Struggling With HPC Workloads in AWS
WuXi NextCODE, a genomics information company that uses genomic data to improve healthcare around the globe, is a groundbreaking user of Cloud Volumes Service for AWS. Their work is immediate and requires enormous processing power to complete.
At the heart of the WuXi NextCODE platform is the genomic relational database, the only relational database designed and optimized to query and analyze massive genomic data. When they attempted to use cloud-based NFS servers and cloud-native file share services to run data sets, they experienced timeouts or file failures.
For scale: Although all humans share a similar DNA sequence, it is not 100% unique to the individual. If you and a friend were to compare your DNA, you would find that in the roughly 3 billion letters of the DNA, you differ in about 5 million locations.
According to Dr. Gudbjartsson, PhD, of WuXi NextCODE, “the challenge is to take a dataset of 5 million and figure out the differences or mutations that are important—which ones are the causes of rare diseases, which ones are the causes of cancer, and how to treat patients”.
HPC in AWS: Addressing the Challenges with Cloud Volumes Service
By taking advantage of NetApp® Cloud Volumes Service, the genomics platform makes it possible to integrate data dynamically to deliver unprecedented computational efficiency.
“A benchmark analysis for analyzing genomic data is generating the allele frequency of every mutation found in a population of 100,000 individuals,” Dr. Hákon Gudbjartsson, PhD, the CIO of WuXi NextCODE, said. “With earlier storage solutions (or self-managed storage), we always had timeouts or file failures. But when we tested this using the NetApp Cloud Volumes Service, it actually finished in less than an hour. That was a great breakthrough for us.”
WuXi NextCODE found that only Cloud Volumes Service delivered the performance they needed to optimize their use of massive genomic data. With Cloud Volumes Service, they can rapidly integrate data on-the-fly to deliver unprecedented computational efficiency to their customers.
Reference Architecture for Configuring HPC on AWS with Cloud Volumes Service
In the architecture diagram below, you can see that the HPC application is configured with NetApp Cloud Volumes Service for AWS. With the combination of backups, snapshot copies, and right-sized throughput, you can easily host your high-performance workloads in the cloud with maximum data protection and nine 9s of data durability.
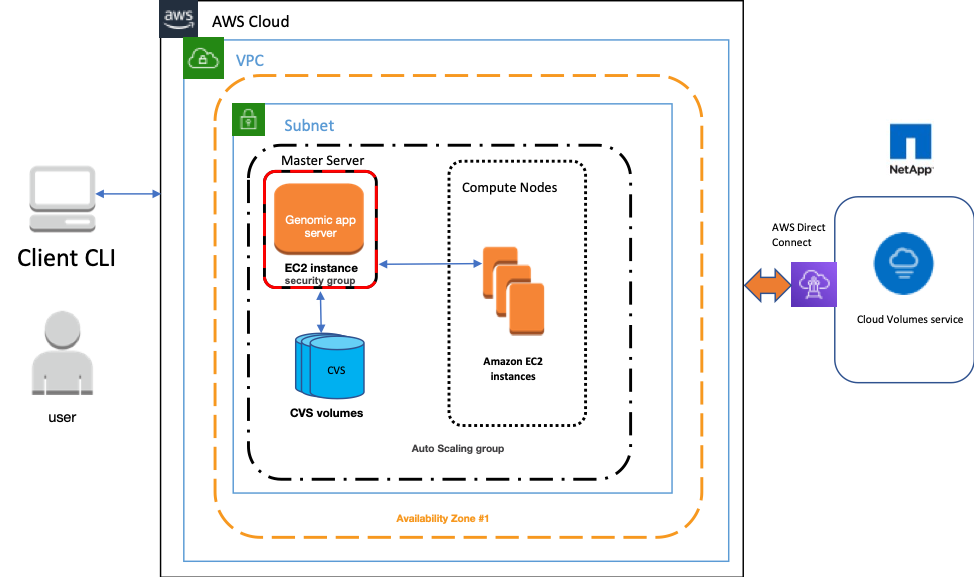

HPC applicationThe key components of the solution include:
- Amazon EC2 instances with autoscaling group.
- NetApp Cloud Volumes Service for AWS (storage)
- NetApp Snapshot Technology
- NetApp Cloud Backup Service
The HPC application is configured on an Amazon EC2 instance with the following attributes.
- Single or multiple cloud volumes are used as the dedicated storage for the datasets.
- The dataset volume(s) are provisioned using the Extreme service class because that class provides the highest throughput at a manageable cost.
- Dataset volume is backed up and restored from the backups rather than creating an individual volume.
- Cloud Backup Service backs data up to the S3 cloud. For more information about the configuration details, please refer to Cloud Backup Service.
Learn More About HPC on AWS
For more information on HPC workloads on AWS, a complete reference architecture, and guidance on how to optimize your service levels for the best cloud spend to usage ratio, check out the full paper.