Share
What is AWS Data Lake?
A data lake is a flexible, cost effective data store that can hold very large quantities of structured and unstructured data. It allows organizations to store data in its original form, and perform search and analytics, transforming the data as needed on an ad hoc basis.
Amazon Web Services (AWS) data lake architectures are typically based on the Simple Storage Service (S3). S3 provides a storage layer for the data lake. There are several AWS big data solutions that can help manage and make use of the data:
- AWS Lake Formation is a managed service that helps automate data lake creation and organize the data
- AWS Glue is used to perform Extract Transform Load (ETL) to transform data within the data lake
- AWS Lambda can be used to process streaming data as it enters the data lake
- Services like Amazon Elasticsearch Service, Amazon Athena and Amazon Elastic Map/Reduce Service (EMR) can be used to analyze and work with the data.
In this article, you will learn:
- Data Lake Architecture with AWS
- AWS Data Lake: Best Practices at Each Stage of the Data Pipeline
- What is AWS Lake Formation?
- AWS Data Lake Q&A
- AWS Data Lake with NetApp Cloud Volumes ONTAP
Data Lake Architecture with AWS
While there are many possible data lake architectures, Amazon provides a reference architecture with the following characteristics:
- Stores datasets of any size in their original form in Amazon Simple Storage Service (S3)
- Uses AWS Glue and Amazon Athena to perform ad hoc transformations and analysis
- Stores user-defined tags in Amazon DynamoDB to context to datasets—this makes it possible to apply governance policies and browse datasets via their metadata
- Uses federated templates to launch a data lake pre-integrated with existing SAML providers like Okta or Active Directory
The architecture is built of three key components:
- Landing zone—ingests raw data from different sources inside and outside the organization. No data modelling or transformation is performed.
- Curation zone—this is where you perform extract-transform-load (ETL), crawling data to understand its structure and value, adding metadata, and applying modeling techniques.
- Production zone—contains data that has undergone processing and is ready for use by business applications or directly by analysts or data scientists.
The following diagram illustrates the architecture:
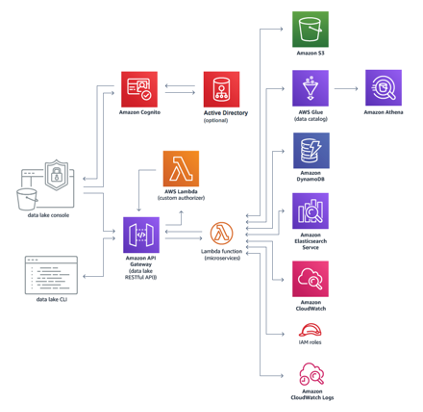 Source: AWS
Source: AWS
How is the reference architecture deployed?
- AWS CloudFormation is used to deploy infrastructure components
- API Gateway and Lambda functions are used to create data packages, ingest data, create manifests, and perform administrative tasks
- The core microservices leverage Amazon S3, Glue, Athena, DynamoDB, Elasticsearch Service, and CloudWatch to facilitate storage, management, and auditing.
- The CloudFormation template deploys a data lake console to an Amazon S3 bucket, with Amazon CloudFront as the access point. It then creates an administrator account and sends an invite to your email address.
Amazon provides ready-made templates you can use to deploy this architecture in your Amazon account.
AWS Data Lake: Best Practices at Each Stage of the Data Pipeline
The following best practices will help you make the most of your AWS data lake deployment.
Ingestion
Amazon recommends ingesting data in its original form and retaining it. Any transformation of the data should be saved to another S3 bucket—this makes it possible to revisit the original data and process it in different ways.
While this is a good practice, it means there will be a lot of old data stored in S3. You should use object lifecycle policies to define when this data should move to an archival storage tier, such as Amazon Glacier. This conserves costs and still gives you access to the data if and when needed.
Organization
Take organization into account right at the beginning of a data lake project:
- Organize data into partitions in different S3 buckets
- Each partition should have keys that can help identify it with common queries
- In the absence of a better organization structure, partition buckets according to day/month/year
Preparation
Treatment and processing should be handled differently for different types of data:
- For dynamically changing data use Redshift or Apache HBase
- For immutable data, store it in S3 and directly perform transformations and analysis
- For fast ingestion, stream data using Kinesis and process it with Apache Flink, then save the results to S3
Learn more in Cloud Data Lake in 5 Steps.
What is AWS Lake Formation?
In the previous section we discussed a simple data lake architecture, which you can set up automatically using a CloudFormation template, and best practices at different stages of the data pipeline. To let you customize your deployment and enable continuous data management, Amazon provides AWS Lake Formation.
Lake Formation is a fully managed service that makes it easy to build, protect, and manage your data lake. It simplifies the complex manual steps typically required to create a data lake, which include:
- Collecting data
- Organizing data
- Moving data into the data lake
- Cleansing data
- Ensuring data is secure
- Making data available for analysis
Lake Formation crawls data sources and automatically moves data into Amazon Simple Storage Service (Amazon S3), to create a data lake.
How does Lake Formation Relate to Other AWS Services?
Lake Formation performs the following tasks, either directly or through other AWS services, including AWS Glue, S3 and AWS database services:
- Registers S3 buckets and paths for your data
- Designs data flows to ingest and transform raw data as needed
- Creates data catalogs with metadata about your data sources
- Defines data access policies for both metadata and actual data through a rights/revocation model
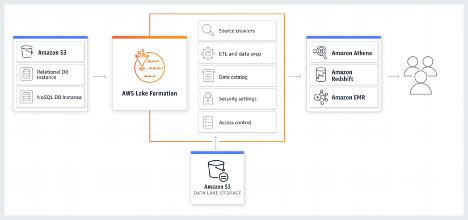 Source: AWS
Source: AWS
Once data is stored in the data lake, end users can select the analytics service of their choice, for example Amazon Athena, Redshift, or EMR, to access and work with the data.
Related content: read our guide to AWS data analytics
AWS Data Lake Q&A
How Does Lake Formation work with AWS IAM?
Lake Formation integrates with Identity and Access Management (IAM), automatically mapping users and roles to data protection policies in the Data Catalog. You can use federated templates to integrate the data lake with Active Directory or LDAP using SAML.
How Does Lake Formation Organize Data in a Data Lake?
Lake Formation organizes data using blueprints. These allow you to ingest data, create Glue workflows that crawl and transform source tables, and load the result to S3. In S3, it organizes data by creating partitions and data formats, and maintains a data catalog with a user interface that lets you search data by type, classification, or free text.
AWS Data Lake with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
Cloud Volumes ONTAP supports advanced features for managing SAN storage in the cloud, catering for NoSQL database systems, as well as NFS shares that can be accessed directly from cloud big data analytics clusters.
In addition, Cloud Volumes ONTAP storage efficiency features, including thin provisioning, data compression and deduplication, and data tiering, will help to reduce your data lake storage footprint and costs by up to 70%.
