Share
What is AWS Data Analytics?
Big data solutions provide capabilities for efficient data analysis. These insights can help organizations leverage data to gain a competitive advantage.
Today’s data management tools have advanced beyond traditional data warehouses to complex architectures capable of addressing sophisticated requirements, such as batch and real-time processing, as well as handling unstructured data and high-velocity transactions.
Amazon Web Services (AWS) offers a wide range of data analytics services, which help quickly design, scale, secure and deploy big data tools. Features vary greatly, with capabilities for collecting, storing, processing and analyzing big data.
Related content: read our guide to AWS Big Data.
In this article, you will learn:
- AWS Big Data Architecture
- AWS Analytics Services
- How to Choose the Right Service?
- AWS Data Analytics with NetApp Cloud Volumes ONTAP
AWS Big Data Architecture
On-Demand Big Data Analytics
AWS enables you to build end-to-end analytics solutions for your business. For example, you can scale Hadoop clusters from 0 to 1,000 of servers in a few minutes, and quickly turn the cluster off as needed. This feature ensures big data workloads can be processed quickly, for a low cost.
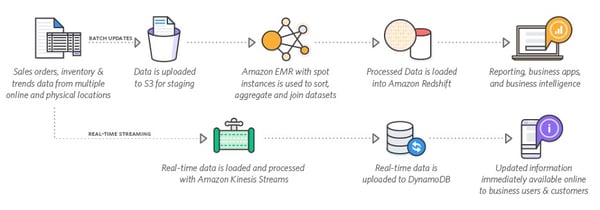 Source: AWS
Source: AWS
Smart Applications
You can leverage Amazon Machine Learning (ML) to enhance your applications with predictive capabilities. Additionally, you can use Amazon Kinesis to ingest data media in real time and then let Amazon ML generate relevant predictions.
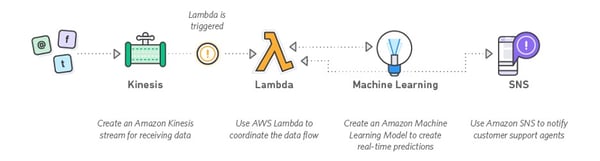
Data Warehousing
When you deploy data warehouses in AWS, you gain tools that help you optimize query performance and reduce costs. Amazon EMR, for example, enables you to perform data transformations (ETL) on Apache Hadoop. You can load the processed data into Amazon Redshift and prepare it for analysis and business intelligence (BI) processes.
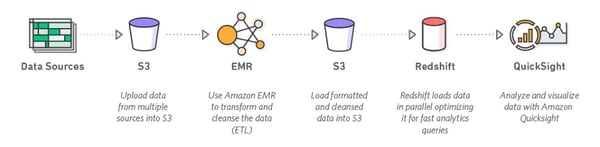
AWS Analytics Services
AWS Athena
Amazon Athena provides capabilities for interactive querying using standard SQL. It helps simplify data analysis in Amazon S3. When using Athena, there is no need to manage infrastructure. Athena is serverless and charged only for queries that were actually performed.
To use Athena, all you need to do is select an Amazon S3 bucket, define a data schema, and you can immediately start querying using SQL. Results are typically delivered in mere seconds. There is no need to run ETL. Anyone with SQL skills can use Athena to prepare data for analysis.
AWS EMR
Amazon EMR offers a managed Hadoop framework for simple, quick, and cost-efficient processing of big data. Amazon EMR also works with other frameworks, including Presto, Apache Spark, Flink, and HBase.
Once integrated, the frameworks can interact with data in many AWS data stores, including Amazon EC2, Amazon DynamoDB, and Amazon S3. EMR provides capabilities for collaborative analysis and ad hoc querying in the form of EMR Notebooks, which are based on Jupyter Notebook.
Related content: read our guide to DynamoDB pricing.
Amazon CloudSearch
CloudSearch offers managed search capabilities, with features for setting up, managing, and scaling search solutions deployed on websites or applications. Notable search features of Amazon CloudSearch include autocomplete, geospatial search, and highlighting. The service currently supports 34 languages.
Amazon Elasticsearch Service
Elasticsearch provides capabilities for searching, analyzing, and visualizing real-time data. The service comes with real-time analytics and APIs, which can be used for full-text search, clickstream analytics, log analytics, and application monitoring.
Amazon Kinesis
Amazon Kinesis provides capabilities for collecting, processing, and analyzing streaming data in real time. You can use Amazon Kinesis to a wide variety of data types, including real-time streams of audio, video, IoT telemetry, website clickstreams, and application logs.
Amazon Kinesis offers four types of services—Kinesis Data Analytics, Kinesis Data Firehose, Kinesis Video Streams, and Kinesis Data Streams.
Amazon Redshift
Redshift is a highly scalable, fast, and cost-efficient data warehouse. To deliver fast performance, Amazon Redshift leverages machine learning with parallel query execution, and columnar storage on high-performance disk.
AWS Data Pipeline
Data Pipeline provides capabilities for processing and transferring data reliably between different AWS services and resources, or on-premises data sources. You can use AWS Data Pipeline to regularly access data storage, then process and transform your data at scale. Results can be easily transferred to AWS services like Amazon RDS, Amazon S3, Amazon EMR, and Amazon DynamoDB.
Related content: read our guide to RDS instance size.
Amazon QuickSight
Amazon QuickSight provides business intelligence capabilities. You can use QuickSight to quickly deliver insights to collaborators. For example, authorized users can create interactive visual dashboards, which are publishable and accessible using either browsers and mobile devices, or integrated with other applications.
AWS Glue
Glue is a fully managed ETL service for loading data and preparing it for analysis. To set up an ETL job, you can simply use your AWS Management Console. Once you point Glue to a data source, it identifies data and metadata, and then stores it in a Glue Catalog. Data in the catalog can then be queried, searched, and stored for future ETL processes.
AWS Lake Formation
Lake Formation provides capabilities for securing data lakes. A data lake serves as a centralized repository, often storing versatile types of data. Data lakes can provide many insights but are difficult to manage. Lake Formation collects and catalogues data, then uses machine learning models to classify and secure sensitive data.
How to Choose the Right Service?
Each use case usually comes with a set of unique characteristics. To ensure you properly assess the situation correctly, ask the following questions:
- Do you need analysis results in seconds, real-time, or an hour?
- What value do you look to gain from the analysis?
- What is your budget?
- What is the scope growth rate of the data?
- How is the schema and structure of the data?
- What integration capabilities exist for data consumption and production?
- How much latency is needed to achieve between data producers and consumers?
- What scope of durability and availability is needed and what is the cost of downtime?
- Do you require consistent or elastic analysis workloads?
AWS Data Analytics with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
In particular, Cloud Volumes ONTAP helps in addressing database workloads challenges in the cloud, and filling the gap between your cloud-based database capabilities and the public cloud resources it runs on. It also manages SAN storage in the cloud, catering for NoSQL database systems, as well as NFS shares that can be accessed directly from cloud big data analytics clusters.

