Share
What Is Azure HPC Cache?
Azure HPC Cache is a distributed file system caching solution offered by Microsoft Azure. It is designed to improve the performance of high-performance computing (HPC) workloads that access frequently used files stored in remote Azure Blob storage. The cache provides a high-speed cache for storing frequently accessed files and data, reducing latency and improving overall performance.
Azure HPC Cache supports multiple hybrid architectures including NFSv3, Dell EMC Isilon, Azure Blob Storage, and other NAS solutions. It can be used to accelerate applications such as genomics, computational fluid dynamics, weather modeling, and many others that require high-throughput access to large datasets.
This is part of a series of articles about HPC on Azure.
In this article:
- How Azure HPC Cache Works
- Azure HPC Cache Use Cases and Examples
- Tutorial: Create an Azure HPC Cache
- Azure Big Data with Cloud Volumes ONTAP
How Azure HPC Cache Works
Azure HPC Cache acts as a caching layer between the HPC cluster and the storage system, allowing frequently accessed data to be stored in a high-speed read and write cache. When an HPC application requests data, HPC Cache checks if the data is already in the cache. If it is, it retrieves the data from the storage cache and returns it to the application, reducing the latency and improving the performance of the application.
HPC Cache uses a distributed caching architecture, with multiple cache servers working together to provide a scalable and highly available caching solution. The cache servers are deployed in an Azure virtual network, allowing them to access the storage system and the HPC cluster.
HPC Cache supports multiple storage protocols, including NFS, SMB, and Azure Blob Storage. It can be deployed in various configurations, including on-premises, in the cloud, or as a hybrid solution.
The solution offers several cache usage models, described in the following table.
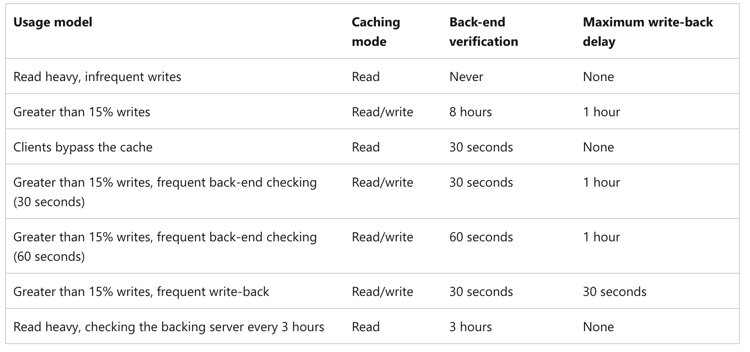
Source: Azure Documentation
Azure HPC Cache Use Cases and Examples
Here are some examples of situations where Azure HPC Cache may be useful.
Read-Heavy Workloads (High Read-to-Write Ratio)
Azure HPC Cache is an excellent solution for workloads that have a high read-to-write ratio. This is because such workloads often involve repeatedly accessing the same files or data, and the cache can store frequently accessed data, reducing the time required to access it.
When the read-to-write ratio is high, it means that there are many more read operations than write operations. In such scenarios, the data is read frequently, but changes to the data are relatively infrequent. In this case, Azure HPC Cache can cache the frequently accessed data and serve it from the cache, eliminating the need to access the remote storage each time.
File-Based Analytics Workloads
HPC Cache is useful for pipelines that use file-based data and involve multiple clients because it provides a shared, high-speed cache for frequently accessed data, reducing latency and improving performance for all clients accessing the data. It helps prevent time-consuming file access from slowing down performance.
Workloads Accessing Remote Data
For workloads that require remote data access Azure HPC Cache provides a distributed file system that can cache frequently accessed data locally, enabling file bursting. It is useful for data-intensive applications that require high-throughput access to large datasets stored in remote locations.
Heavy Request Loads
HPC Cache helps accelerate file access when many clients are simultaneously requesting data from the same source. It does this by caching frequently accessed data in a shared cache, reducing the number of requests to the remote source. This improves overall performance for all clients. This makes it a highly scalable solution.
Azure-Based Resources
HPC Cache brings data closer to Azure virtual machines by caching frequently accessed data in a high-speed cache that is located near them. Virtual machines are scalable, cost-effective resources for high-performance computing workloads. HPC Cache is suitable for resources located in Azure because it is a cloud-native solution that integrates seamlessly with other Azure services.
With Azure HPC Cache, there is no need to re-architect the pipelines to make Azure-native calls to the blob storage. The data is accessible from its source system or a blob container in Azure.
Learn more in our detailed guide to HPC use cases.
Tutorial: Create an Azure HPC Cache
You can create a cache using the Azure CLI or portal. Here's a quick tutorial on how to create an HPC Cache using the Azure portal:
- Log in to the portal (https://portal.azure.com) using your credentials.
- Create a new HPC Cache resource by clicking on Create a resource in the left-hand menu and searching for HPC Cache in the search bar.
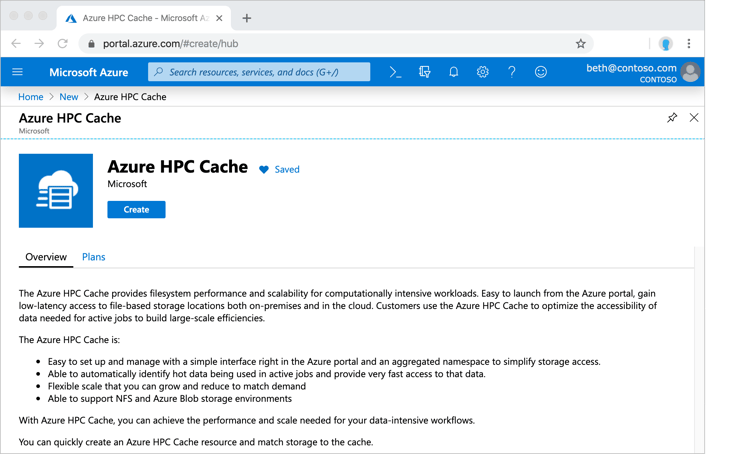
Image Source: Azure - In the Basics tab, provide a name for the HPC Cache, select the subscription you want to use, and specify the resource group (you can create a new group or choose an existing one).
- In the Service details section, select the location where you intend to create the HPC Cache. You can choose from any available Azure region. Next, select the virtual network and subnet where the cache will be located. If you don't have a virtual network set up yet, you'll need to create one first.
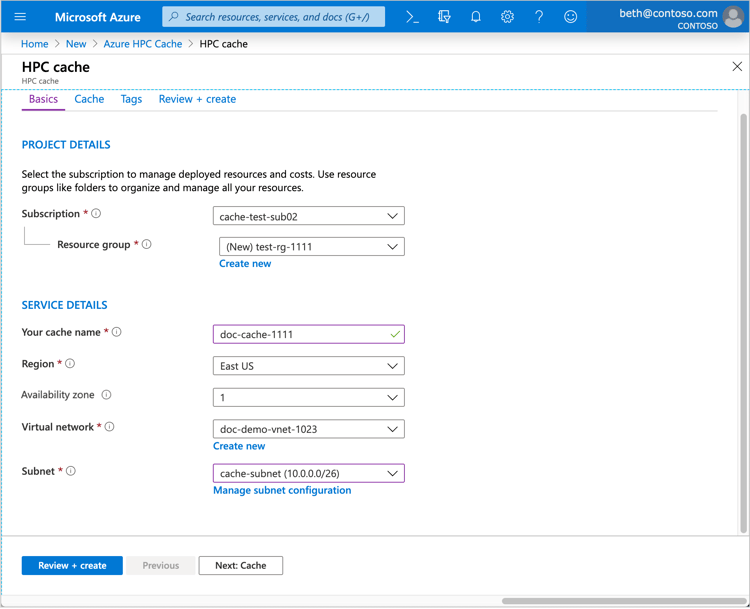
Image Source: Azure - Next, select the cache type. There are two options: Standard or Premium. The Standard cache is suitable for workloads that require low to moderate performance, while the Premium cache is designed for high-performance workloads. You'll also need to choose whether the cache will be read-write standard, read-only, or read-write premium.
- Choose the right cache size and throughput. The size of the cache determines how much data it can store, while the throughput determines how much data can be read or written per second. The right size and throughput will depend on the needs of your workload.
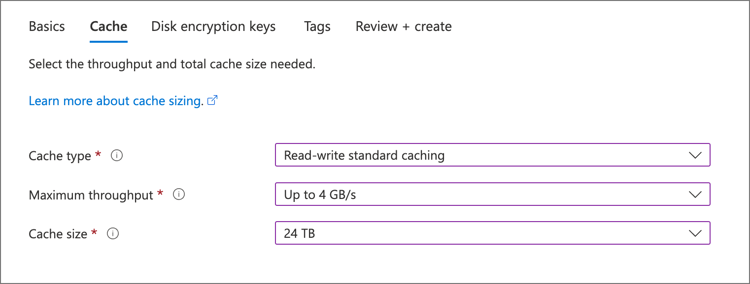
Image Source: Azure - Review the configuration and pricing details to ensure that everything is correct. You can also configure advanced settings like tagging and backup options.
- Click "Create" to create the cache. This process usually takes around 10 minutes to complete.
Image Source: Azure
Once the cache is created, you can start using it to accelerate data access for your workloads. You'll need to configure your virtual machines or other compute resources to use the cache, which can be done using standard HPC protocols like NFS, SMB, or Lustre.
Azure Big Data with Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure, and Google Cloud. Cloud Volumes ONTAP capacity can scale into the petabytes, and it supports various use cases such as file services, databases, DevOps, or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
These NetApp caching features help minimize access latencies:
- Edge Caching for caching data at the edge of the network reduces access latencies and enables collaboration among distributed users accessing the same file from remote locations. Central file locking makes sure collaboration happens in real time, preventing multiple users from making changes separately so file data stays consistent.
- FlexCache Volumes create local caches of frequently accessed data, reducing the need to access remote file storage and improving overall data access times. Cloud bursting through FlexCache helps scale storage infrastructure dynamically by using cloud resources during periods of high demand. This can help ensure optimal performance and reduce access latencies, even during periods of peak usage.

