Share
What is Azure Disaster Recovery?
A business continuity and disaster recovery (BCDR) strategy helps organizations secure data, applications, and workloads during planned or unplanned outages.
To help organizations implement BCDR, Azure provides Azure Site Recovery (ASR). ASR ensures business continuity during outages by replicating applications and workloads from their primary location to a secondary site.
This post covers two common DR architectures: Azure-to-Azure disaster recovery and physical server to Azure disaster recovery.
This article is part of our series of articles on Azure Backup.
In this article, you will learn:
- What is Azure Site Recovery?
- Azure to Azure DR with Azure Site Recovery
- Physical Server to Azure DR with Azure Site Recovery
- Azure Disaster Recovery with NetApp Cloud Volumes ONTAP
What is Azure Site Recovery?
Azure Site Recovery (ASR) is a disaster recovery as a service (DRaaS) that can be used in both public cloud and hybrid cloud architectures. It lets you use Azure as an on-demand disaster recovery site, without needing to invest in disaster recovery equipment upfront.
ASR creates replicas of computer systems which are synchronized through a near-real-time data replication process. It provides application-consistent snapshots, which make sure data is usable after a failover.
ASR provides support for several migration and disaster recovery scenarios:
- Replicating physical servers from on-premises data centers and other cloud providers to Azure
- Replicating virtual machines (VMs) (both Windows and Linux) running on VMware or Microsoft Hyper-V infrastructure to Azure
- Replicating VMs (Windows only) from AWS to Azure
- Replicating VMs (both Windows and Linux) from Azure Stack, Azure’s hybrid cloud solution, to Azure
Azure to Azure DR with Azure Site Recovery
Azure Site Recovery continuously replicates Azure VMs to different regions, which serve as a secondary location. In case of an outage, organizations can use the secondary region to access their data and workloads - this is known as failover. Once the primary site works, normal operations can resume there - this is called failback.
Note: ASR is only supported between two regions in the same geographical cluster (for more details see the documentation). VMs you want to replicate must run one of the supported operating systems (which include most popular versions of Windows and Linux).
Here are the components involved in this process:
- VMs in the source region - one or more Azure VMs running in the source region.
- Source VM storage - Azure VMs that are either managed or using unmanaged disks that are distributed across storage accounts.
- Source VM networks - you can place VMs in 1 or more virtual network (VNet) subnets located in the source region.
- Cache storage account - should be in the source network. VM changes are stored in this cache before they are sent to a target storage. This can help reduce impact on production applications. Azure advises to use only Standard cache storage accounts.
- Target resources - used during replication and when outages occur. Site Recovery sets up the target resources by default. It is also possible to create and customize the resources.
Snapshots and Recovery Points
Site Recovery takes snapshots of VM disks. By default, the system takes crash-consistent snapshots of data. It is possible to define a frequency, and then Site Recovery will take app-consistent snapshots.
The Site Recovery system uses snapshots to create recovery points, and then stores them according to the retention configurations pre-defined in the replication policy. Once a failure occurs, Site Recovery lets you restore a VM from a recovery point.
This process helps ensure VMs start with no data loss or corruption. Depending on the snapshot taken, the process also helps make sure VM data remains consistent for the OS and the applications running on the VM.
Replication Process
The replication process performs several actions. First, the system installs the service extension of Site Recovery Mobility on the virtual machine. The extension can then register the virtual machine with Site Recovery. Then, the system starts continuously replicating the VM, immediately transferring disk writes to the Standard cache storage that was set up in the source location.
During the next phase, Site Recovery starts processing cache data, sending it to replicated managed disks or to a storage account. When this is done, the system starts generating crash-consistent recovery points every 5 minutes. If the replication policy defined a process for app-consistent recovery points, these will be created too.
The following diagram shows what happens when you enable replication. ASR starts replicating disk data to the target environment. However, virtual machines are not started yet.
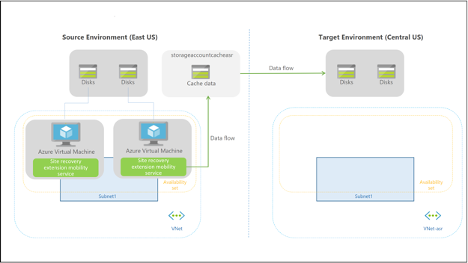 Source: Azure
Source: Azure
Failover
When you initiate a failover via ASR, VMs are created in the target region based on the virtual network, subnet, and availability set you defined, and the data previously replicated from the source environment.
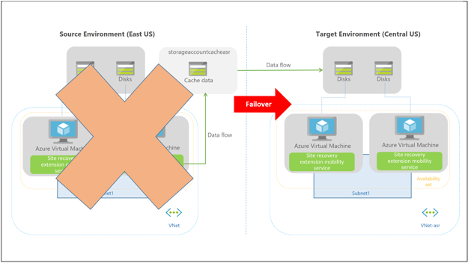 Source: Azure
Source: Azure
Physical Server to Azure DR with Azure Site Recovery
Azure Site Recovery can also be used to replicate physical servers deployed in an on-premises data center to the Azure cloud.
Here are the components involved in the process:
- Azure subscription and network - data replicated from physical machines is copied to disks within your Azure subscription. When you perform a failover, Azure VMs are created from data in those disks, within an Azure virtual network of your choice.
- Process and configuration server - a replication gateway that receives data from local machines, applies caching, compression, and encryption, and copies to Azure storage. Also enables central management of the replication process. For large deployments, you may need several process servers, one for each group of machines.
- Master target server - also deployed on-premises, this server performs replication back to the on-premises data center during failback. As with process servers, several may be required for large deployments.
- Mobility service - installed on each service you want to replicate to Azure. Microsoft recommends automatically installing the mobility service from the process server. You can also install it manually if needed.
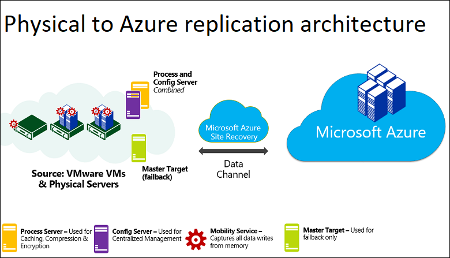 Source: Azure
Source: Azure
Replication Process
When replicating an on-premises physical server to Azure, replication works as follows:
1. You set up a deployment with local and Azure components. Recovery Services Vault specifies a replication source and destination, sets up a configuration server, creates a replication policy, and enables replication.
2. ASR replicates an initial copy of server data to Azure storage, using the predefined replication strategy.
3. When the first copy is complete, ASR begins copying incremental changes to Azure. Changes are tracked using a log file with extension .HRL.
4. Traffic can be rerouted to the new machine on Azure over the Internet or using Azure ExpressRoute with public peering.
Failover Process
In case of a disaster the failover process from the on-premises data center to Azure works as follows:
1. You select the VM you want to fail over.
2. You select a recovery point to fail over to. There are several options:
a. Latest - provides the lowest Recovery Point Objective (RPO), by failing over to the very latest version of the on-premises server. This option is crash consistent.
b. Latest processed - provides the lowest RTO (Recovery Time Objective) because it doesn’t wait for processing of the latest replicated data, instead using the latest version that is ready for failover. This option is also crash consistent.
c. Latest app-consistent - fails over using the latest recovery point that is app consistent, guaranteeing that application data is not corrupted.
d. Custom - lets you set a recovery point manually.
3. You can optionally shut down the source machine before starting the failover (but failover continues even if this fails)
4. Failover begins - the Azure Site Recovery Jobs page shows progress.
5. When failover ends, connect to the target VM to validate it works correctly, and then commit the failover. This deletes all other available recovery points.
After failing over to Azure, you may need to re-protect Azure VMs by replicating them back to the on-premises site. This is a detailed procedure - see the documentation for more details.
Failback Process
When your primary on-premises site is available again, you can fail back as follows.
Note: ASR failback requires a local VMware environment - even if you originally protected physical machines. ASR is only able to fail back to VMware VMs in your local data center.
In the ASR console, you select the VM you need to fail back, and request “unplanned failover”. Failback is called “failover” in ASR - make sure you select the failover direction as “from Azure”.
- You select the recovery point for failback - the same options are available as detailed in the failover process above. Microsoft recommends using Latest, a crash-consistent recovery point. You may lose some data if you select app-consistent.
- While failover is running, ASR shuts down the Azure VMs, and starts up the on-premises VMware VM. Expect some downtime during this process.
- Commit the failback - this starts a job that removes Azure VMs, as they are no longer needed. Microsoft advises verifying that VMs have shut down correctly.
See the Azure documentation for more details, and guidance for automating some of these steps for faster failover and recovery.
Azure Disaster Recovery with NetApp Cloud Volumes ONTAP
While Azure offers some capable disaster recovery solutions on its own, users can get more protection and better DR processes, all at a lower cost, with NetApp Cloud Volumes ONTAP.
Cloud Volumes ONTAP brings the trusted enterprise-class storage management features of on-prem ONTAP storage systems to Azure. It can reinforce your DR strategy in Azure, serving as the underlying storage management system, or serve as a DR storage management on its own. In either case, Cloud Volumes ONTAP adds value with features such as data replication, high availability, and storage efficiency, as we’ll see below.
Ensure Cloud Business Continuity
The Cloud Volumes ONTAP HA (High Availability) configuration for Azure uses shared storage between two Cloud Volumes ONTAP nodes that are part of different fault and update domains. In the event that one of the nodes becomes unavailable, the surviving node takes over and provides access to data without any disruption.
Easy Azure storage replication
Cloud Volumes ONTAP uses SnapMirror® technology to replicate data across hybrid and multicloud architectures. It can be used to replicate data to a secondary site for DR and keep it in sync. SnapMirror replication is set up using the simple drag-and-drop controls in NetApp Cloud Manager.
Failover and Failback
A failover can be initiated by breaking the replication relationship in SnapMirror. During failback the synchronization can be reversed and data from the DR site can be replicated back to the primary location.
Storage Efficiencies
Cloud Volumes ONTAP’s storage efficiency features, including thin-provisioning, data compression, deduplication, and data tiering, help to reduce the DR copy’s storage footprint and costs. These features are available out of the box and can be used by the customer with no configuration overheads.
FlexClone for DR Testing
Cloud Volumes ONTAP data cloning technology can be used to clone instant, writable volumes for DR testing that won’t affect ongoing operations. These volumes are created instantly, and with zero capacity penalty.

