Share
What is Google Cloud Data Lake?
A data lake is a central repository designed to store, process, and protect large volumes of structured, semi-structured and unstructured data. You can store the data in its native format and use a variety of data without considering size limitations.
GCP offers a set of automated scaling services that allow you to build a data lake that integrates with your existing applications, technologies, and IT investments. These include Dataflow and Cloud Data Fusion for data absorption, Cloud Storage for storage, and Dataproc and BigQuery for processing data and analytics.
Google structures its data lake services across four key phases in the data lake lifecycle. We’ll describe the lifecycle, and which tools and services Google Cloud offers that can help you implement each phase.
This is part of our series of articles about Google Cloud Database services.
In this article, you will learn:
- Google Cloud Data Lake Lifecycle
- Phase 1: Ingest
- Phase 2: Store
- Phase 3: Process and Analyze
- Phase 4: Explore and Visualize
- Google Cloud Data Lake with NetApp Cloud Volumes ONTAP
Google Cloud Data Lake Lifecycle
Google Cloud provides tools and workflows to manage data lakes throughout their lifecycle. Google defines four stages in a data lake lifecycle:
- Ingestion—allowing data from numerous sources, such as data streams from events, logs and IoT devices, historic data stores, data from transactional applications, to feed into the data lake.
- Storage—storing the data in a durable and easily accessible format.
- Processing—transforming data from its original format into a format that enables usage and analysis.
- Exploration and Visualization—performing analysis on the data and presenting it as visualizations or reports that provide insights for business users.
Related content: read our guide to Google Cloud Big Data
Phase 1: Ingest
There are several approaches to collecting raw data for a data lake. Which you choose depends on the size, source, and latency of the data.
Data commonly stored in a data lake includes:
- Application event data, including log files and user events
- Small, asynchronous messages sent as part of streaming event pipelines
- Large volumes of data batches, typically in a file-based format
The chart below illustrates the manner in which Google Cloud maps services to application data, streaming data, and batch workloads.
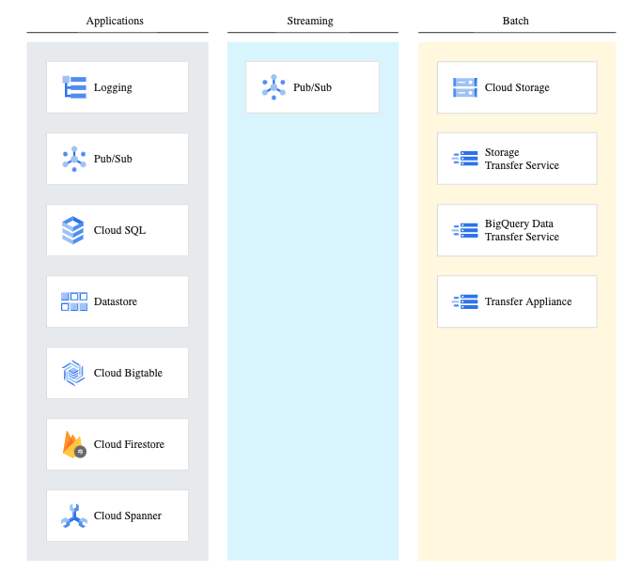 Source: Google Cloud
Source: Google Cloud
Related Tools
The following Google Cloud tools can be a part of the ingestion phase in a data lake.
Cloud Logging—includes a log repository, a user interface called Log Explorer, and an API for managing logs programmatically. You can use it to control how log entries are read and written, how logs are queried, and how logs are routed and used. Cloud Logging can help route specific types of logs to the data lake for processing and analysis.
Pub/Sub—a messaging service that allows components to publish messages to topics, while other components can subscribe and listen to those messages in an asynchronous manner. Pub/Sub can be used as a middleware, or for event capture and streaming data analysis. A data lake can be a destination for event streams, and Google Functions can be used to process events in real time as they are ingested to the data lake.
Databases—you can ingest data from Google database services like Google Cloud SQL, Cloud Datastore, Bigtable, Cloud Firestore, and Cloud Spanner.
Batch jobs—you can transfer data in batch from Google Cloud Storage, from BigQuery, using the BigQuery Data Transfer Service, or from on-premises data stores, using the Google Storage Transfer Service or Transfer Appliance.
Phase 2: Store
Data lakes store a huge variety of data sources. The structure of the data lake, as well as its uses by business users and applications, are dependent on the nature of the data. Data storage solutions in a data lake need to adapt to the types and uses of the data within it.
The following diagram shows how Google Cloud stores three types of data:
- Structured data—including transactional and analytical workloads
- Semi-structured data—including fully indexed data and datasets only identified by row key
- Completely unstructured data
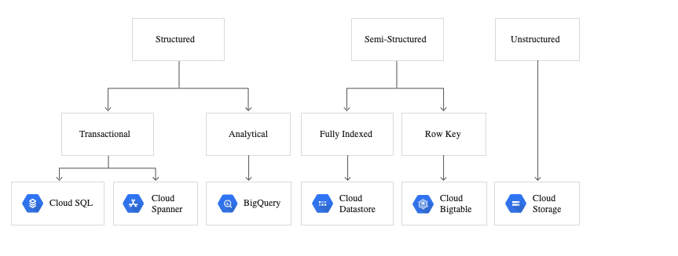 Source: Google Cloud
Source: Google Cloud
Related Tools
The following Google Cloud tools are commonly used to store data as part of a data lake deployment:
Cloud Storage—it is common to store data lake unstructured content in Google’s elastically scalable object storage service.
Cloud Datastore—a NoSQL document database providing SQL-like query syntax, supporting high performance and ease of development.
Cloud Firestore—a flexible database service designed for mobile and web applications. Enables offline access to data, by synchronizing data with client applications with real time listeners.
Related content: read our guide to Google Cloud Firestore
Cloud Bigtable—sparse table that can support billions of rows and thousands of columns, storing up to petabytes of data with low latency and high throughput.
Cloud SQL—Google’s database service supporting common database engines like MySQL and PostgreSQL.
Related content: read our guide to Google Cloud SQL
Cloud Spanner—Google’s fully managed relational database service, suitable for mission critical transactional applications.
BigQuery—Google BigQuery can be used to store analytics workloads requiring very fast query performance.
Phase 3: Process
To maximize the value of datasets, you must be able to transform it into usable form. An effective processing framework can either directly analyze the data, or prepare it for analysis downstream. It also provides analytic tools to interpret the results of data processing.
The first step is to process source data, clean and normalize it. Then, it is typically distributed across multiple physical machines for processing and stored. Finally, analytics systems are deployed to allow ad-hoc querying and exploration of the data, as well as training and testing of machine learning models.
Related Tools
The following diagram shows tools provided by Google Cloud, which can be part of the processing phase in a data lake.
 Source: Google Cloud
Source: Google Cloud
Cloud Dataproc—a managed service that lets you use Spark and Hadoop to perform large-scale batch processing. Automates creation and management of Hadoop clusters.
Cloud Dataflow—a data processing service that lets you set up data pipelines in order to integrate and analyze multiple data sources.
Cloud Dataprep—a service that lets you explore, prepare, and clean large-scale data sets for analysis. Dataprep is based on a serverless architecture so it can scale on demand, without the need to manage servers or infrastructure.
Related content: read our guide to Google Cloud Analytics
Phase 4: Explore and Visualize
Here are some of the tools Google Cloud provides in the final stage of the data lake lifecycle, to help you explore data and derive insights that can provide business value:
- Datalab—a web-based interface for slicing, dicing, and visualizing large datasets.
- Looker—lets you perform business intelligence tasks, create custom data applications, and set up custom data workflows.
- Data Studio—a no-code visual interface that lets you build reports and create dashboards to share insights with others in the organization.
- Data Catalog—a metadata management service that enables large-scale data discovery, applying Google’s search technology to your own data assets.
Learn more about building a cloud data lake here: Cloud Data Lake in 5 Steps
Google Cloud Data Lake with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
Cloud Volumes ONTAP supports advanced features for managing SAN storage in the cloud, catering for NoSQL database systems, as well as NFS shares that can be accessed directly from cloud big data analytics clusters.
In addition, Cloud Volumes ONTAP provides storage efficiency features, including thin provisioning, data compression, and deduplication, reducing the storage footprint and costs by up to 70%.

