Share
The OpenShift Container Platform is designed as a microservices-based architecture, running on a Kubernetes cluster. Data about objects managed by the OpenShift platform is stored in etcd, part of the Kubernetes control plane, which is a clustered, reliable key-value store.
In OpenShift, each service is broken down according to functionality. REST APIs expose each core object. To change system state, users can make calls to a REST API.
OpenShift is based on Kubernetes controllers, which receive user requirements, apply the necessary changes to objects, and continuously ensure the cluster is in sync with those requirements. Each controller exposes its own REST API.
To make functionality extensible, OpenShift Container Platform uses controller patterns. This makes it possible to customize, launch, and run each build independently from the way in which images are deployed or managed.
Customizing controllers can help you modify the logic and implement different behaviors. You can also use APIs to automate and schedule common tasks. In this case, each script serves as a controller that tracks changes and takes actions.
In this article, you will learn:
- OpenShift Container Platform Core Concepts
- OpenShift Layers and Components
- Red Hat OpenShift Storage with Cloud Volumes ONTAP
OpenShift Container Platform Core Concepts
1. Containers
Containers are the basic units of an OpenShift Container Platform application. They are a lightweight mechanism for isolating processes and can only interact with specified resources on the host machine.
You can use Kubernetes and OpenShift Container Platform to orchestrate Docker containers across multiple hosts. You operate clusters using native Kubernetes mechanisms and the Docker CLI.
Learn more in our introduction to Kubernetes guide
2. Images
OpenShift Container Platform uses standard Docker images to create containers. Images are binaries that include all requirements for running containers, along with descriptive metadata. You can build images as you would in plain Docker, using the Docker CLI, or leverage a library of OpenShift base images.
3. Container Image Registries
An image registry is necessary to manage container images and allow OpenShift to store and retrieve images when provisioning resources. You can use either Docker Hub, any other registry, or the OpenShift Container Platform’s internal image registry.
4. Pods
In Kubernetes, a pod is the smallest operating unit of a cluster, letting you deploy one or more containers on a host machine, and scale out to additional machines as needed. Pods are roughly equivalent to machine instances, with each pod having an internal IP address and its own port space—the containers in a pod share networking and local storage.
OpenShift Container Platform doesn’t support changes to pod definitions while they are running. Changes are implemented by terminating a pod and recreating a modified version. Pods are expendable and don’t maintain state when reconstituted, so they should be managed by a higher-level controller and not by users.
5. Services
Kubernetes services act as internal load balancers—they identify sets of replicated pods and help proxy their connections. You can add or remove pods from a service, and the service always remains available, allowing other objects to refer to the service’s consistent address. Default service clusterIP addresses allow pods to access each other.
6. Users
Users are the agents that interact with the OpenShift Container Platform—user objects can be given role-based permissions, either individually or as groups. Users must authenticate to access the platform; unauthenticated API requests are treated as requests by an anonymous user. Roles and policies determine what each user is authorized to do.
7. Builds
Builds are the process of creating an object based on input parameters, usually resulting in a runnable image. BuildConfig objects are definitions for entire build processes. OpenShift Container Platform creates Docker containers from build images and pushes them to a container image registry.
8. Image Streams
Image streams and their associated tags provide abstractions for referencing container images in OpenShift Container Platform. They do not contain image data, but rather present a visualization of related images and changes made to them. You can set up builds and deployments that respond to image stream notifications.
OpenShift Layers and Components
The following diagram shows several key OpenShift architectural layers and components. These are explained in more detail below.
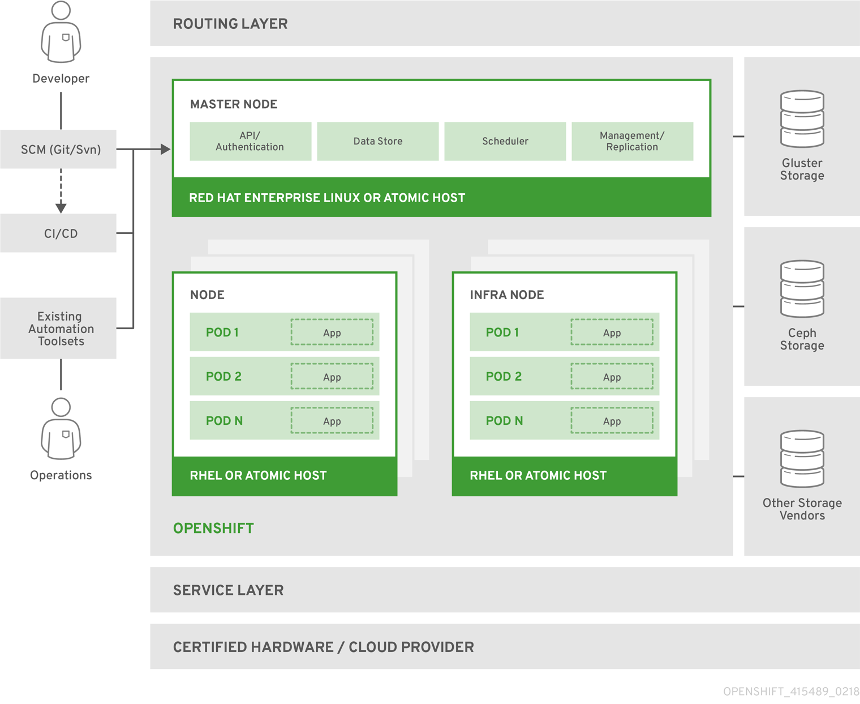 Image Source: OpenShift
Image Source: OpenShift
Infrastructure Layer
This layer lets you host applications on virtual servers or physical servers, as well as private or public cloud infrastructure.
Service Layer
This layer lets you define pods and access policies. Here are several features of the service layer:
- Provides a permanent IP address and host name for your pods.
- Lets you connect applications together
- Enables you to use simple internal load balancing for distributing tasks across multiple application components.
The service layer runs your clusters. An OpenShift cluster uses two types of nodes—main nodes (responsible for managing the cluster, also called master nodes) and worker nodes (responsible for running applications).
Main Nodes
Main nodes are in charge of managing the OpenShift cluster, performing four key tasks:
- API and authentication—administration requests must go through APIs. Each request is encrypted by SSL and authenticated to ensure the cluster remains secure.
- Data store—the state and any information related to the environment and application is kept in data stores.
- Scheduler—pod placements are determined by schedulers, which take into account the current environment and utilization aspects like CPU and memory.
- Health and scaling—health of pods is monitored and scaled by self-healing and auto-scaling processes that take into account CPU utilization. Once a pod fails, the main node automatically restarts it. If a pod fails too often, the automated process marks it as a bad pod and stops restarting it for a temporary period of time.
Worker Nodes
Each worker consists of pods. In OpenShift, a pod is the smallest unit you can define, deploy, and manage. A pod can host one or more containers.
A container hosts applications and relevant dependencies. You can deploy containers as stateless or stateful.
Containers located in the same pod share an IP address, local storage, and attached storage volumes. A pod can host a sidecar container, which you can use to add components like a service mesh, logging or monitoring tools.
Persistent Storage
Containers are ephemeral and are often restarted or deleted. This is not ideal for storing data. To prevent data loss, you can use persistent storage, which lets you define stateful applications and data.
Learn more in our detailed guide to Red Hat OpenShift Container storage.
Routing Layer
This layer provides external access to cluster applications from any device. The routing layer also performs auto-routing and load balancing for unhealthy pods.
Red Hat OpenShift Storage with Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP capacity can scale into the petabytes, and it supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
In particular, Cloud Volumes ONTAP supports Kubernetes Persistent Volume provisioning and management requirements of containerized workloads.
Learn more about how Cloud Volumes ONTAP helps to address the challenges of containerized applications in these Kubernetes Workloads with Cloud Volumes ONTAP Case Studies.

