Share
Last week I posted an article on LinkedIn that detailed how to roll out Cloud Insights collectors to hundreds of servers and applications, quickly and effectively, using Ansible. But this method alone doesn’t solve the conundrum of monitoring at scale; it just makes it easier to collect metrics in the first place.
The Oxford English dictionary defines “monitor” as “observe and check the progress or quality of (something) over a period of time” (or “a large tropical Old World lizard”, but we’ll use that first definition here). So, step two of solving the challenge of monitoring at scale is identifying ways to observe these metrics at scale.
The approach I’m endorsing in this blog may be a little bit different than what you might expect. Typically, in an enterprise IT department, lots of different people have different skill sets, and each monitors and maintains their own part of the IT stack using deep-dive element management tooling that’s designed for just that purpose.
I’m not about to suggest these deep dive tools can just be scrapped in favor of a single-pane solution. Those IT teams likely have decades of collective experience using these tools, and there’s value in specialized element management tools that can’t be replicated with any heterogeneous tool. One thing that element managers can’t do, however, is scale. And by ‘scale’, I don’t mean scale with the number of database instances, cluster nodes, web proxies, or virtual machines under management. I’m referring to scaling the number of people using, and most importantly understanding, the information and insight that these tools provide.
Effective Monitoring at Scale
To most effectively monitor at scale, you need a monitoring tool that covers as much of your environment as possible. But you also need to equip as many users as possible with an understanding of that tool that will allow them to take action based on its reporting. Training up everyone in your IT organization as a cross-domain technical wizard is expensive and impractical, so what’s the alternative? Make sure your tooling can democratize IT. Anyone in an organization, regardless of technical ability, should be empowered to consult an at-a-glance view of application performance and identify an issue—and even the component of your infrastructure that’s at fault.
A Storage Brainteaser: What’s Working? What’s Not?
Here’s an example of an application in NetApp’s environment. The application is built from Apache, HAProxy, MySQL and MongoDB, and it’s running on a handful of virtual machines, both on premises and in the cloud (and on NetApp storage, of course). I’m not going to tell you what it does, who is using it, or what level of performance end users expect.
Armed with precisely zero background information about this application, I’d like you, the reader, to figure out if this application is healthy or not. Fortunately, to help you out, we’re monitoring all of the components in this application stack with Cloud Insights, and the owners from each layer of that stack have highlighted their key performance indicators.
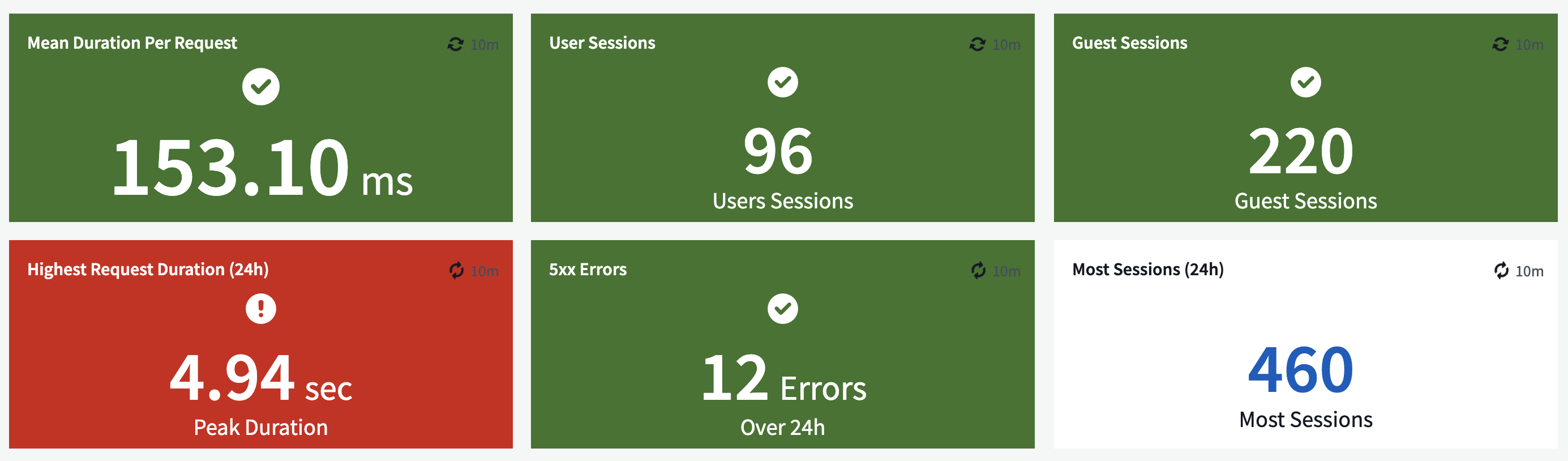
The application owner has identified their key signals for application health, as well as the number of currently active users. Not knowing anything else about this application, we’ll assume that the average request duration, number of 5xx errors, and active users are all within tolerable limits, and the green boxes above support that assumption. Where we appear to have an issue, however, is the peak request duration. Without any context, this wouldn’t be enough information to tell me whether there is a problem or not, but the application owner has defined a threshold of what is, and isn’t, okay. Judging from the red highlight and exclamation point, it’s not a stretch to assume that this application is in trouble.
So far, so good. Or bad, in this case. Now, still armed with zero prior knowledge of this application, let’s try to single out the component that’s causing the problem.
Here you can see the web layer of this application, and much like the application owner has, the web admin has highlighted key signals here.
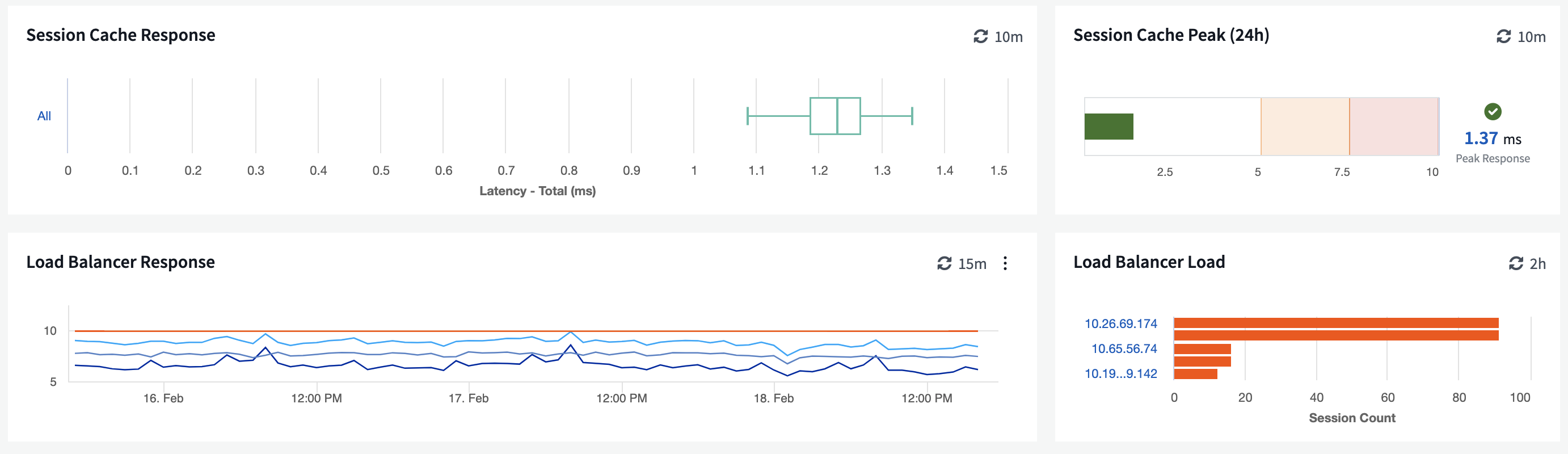
Nothing jumps off the page, so even if we don’t understand what these metrics really mean, we can be pretty confident that there are no problems here and move on to the next layer.
As we navigate further down this application stack, things get more interesting. MongoDB appears to be healthy, but there’s no doubt that there’s been a MySQL issue here. 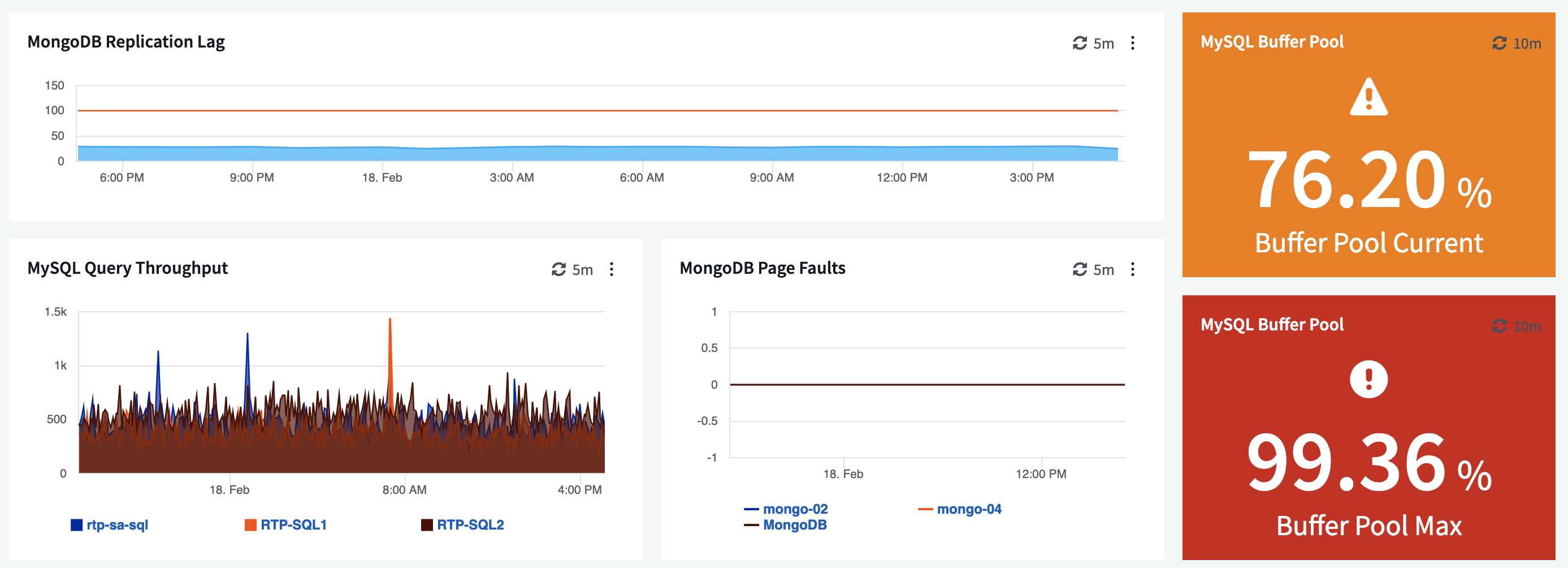
At this point, you may be tempted to pin the blame on the database layer and those responsible, but if you move over to the compute side of things, you get a different story. Fortunately for the DB admins, getting a view of all of these attributes is simply a matter of scrolling a little further down the page.
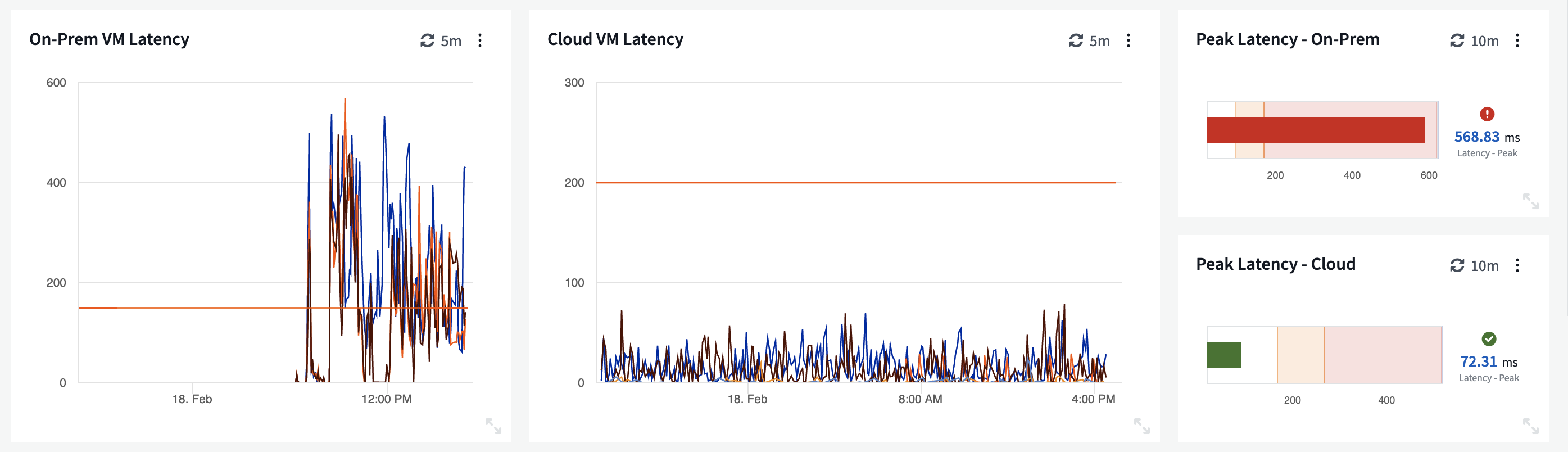
Bad times indeed! There’s definitely an issue with our on-premises virtual machines: Latency is through the roof! If you were to jump to conclusions here, you might blame the storage team. After all, latency is a function of storage performance, right? If we continue our troubleshooting quest, however, we see that the storage KPIs are looking pretty healthy.
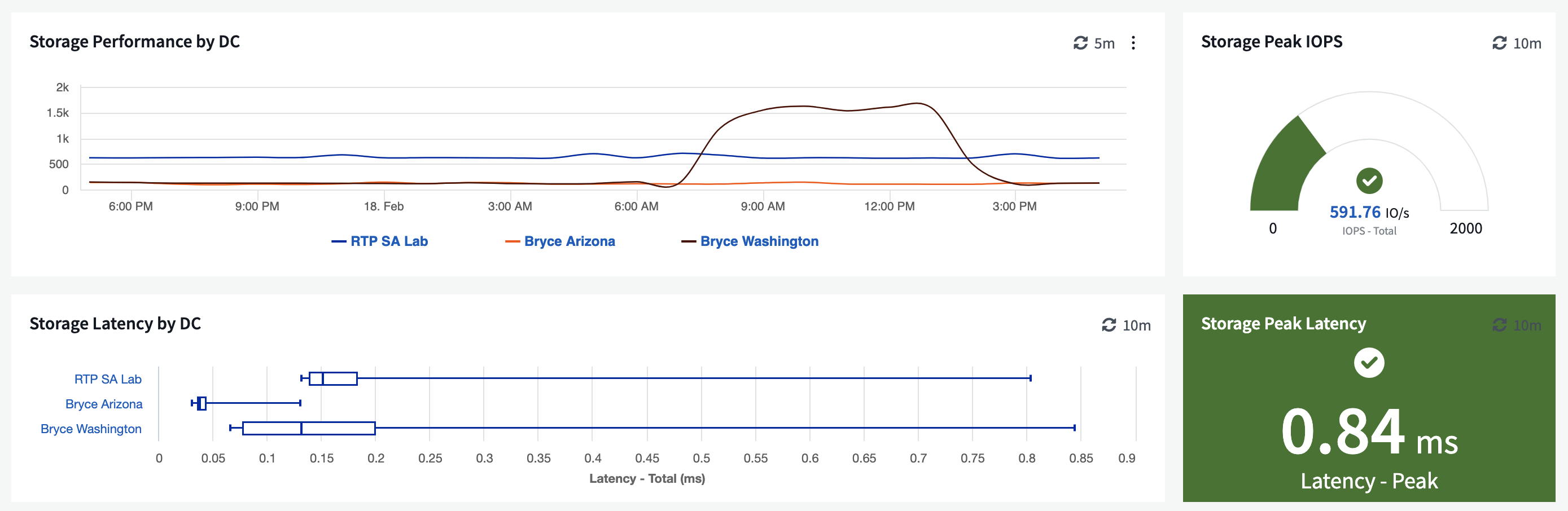
Those of you with storage roles will almost certainly have, at one point, gotten the blame for a latency issue—but further inspection of the storage element managers reveals that nothing is wrong. It’s notoriously difficult prove to other teams that your infrastructure is healthy when you’re trying to use specialized storage tools to do so. In this application overview, it’s clear: While there is a problem with latency in these VMs, there’s no such issue in the storage, which has sub-millisecond peak latency across the board.
In this example, it’s obvious that the on-premises compute infrastructure needs to be investigated more deeply. This team can click through to expert views directly from this dashboard, and even link to external element management tools to continue working on the problem until it’s resolved.
Compressing Incident Resolution Timeline
What we haven’t done in this blog is identify the exact incident resolution steps needed to fix this issue, but this wasn’t the goal. Every layer in IT stack has different experts that build and maintain it, and they’re on the hook for fixing the problem. In this example, the administrators are responsible for inspecting on-premises VMs.
The objective with any issue or outage is to resolve it as quickly as possible. If you consider the timeline of an incident, you can split it into two parts: first finding the problem, and then fixing the problem. Fixing the problem is a case of domain experts doing what they do best, and getting it done quickly means having either more experts or better experts. That’s easier said than done, and not really something tooling can help with, anyway. Before these experts can work on fixing the problem, however, they need to know where the problem is.
The ever-increasing complexity of IT often means that identifying the source of a problem takes up far more time than actually implementing a fix. With Cloud Insights' highly accessible view of application performance, you can greatly compress the first half of this timeline. That means two things: Experts can start working on a fix more quickly, and everyone else can get back to their day jobs. And anyone that has ever spent hours sitting on conference calls for “all hands on deck” incidents will certainly agree that’s not a bad thing!
Try It Out Now.
If you want to see just how effective democratized monitoring can be in your own environment, get started with a 30-day free trial of Cloud Insights today.
