Share
Data privacy is currently one of the hottest topics in big data, and with good reason. A succession of new data protection laws have been coming into force across the globe in response to today’s data-driven landscape. As a result, data architects and data engineers now need to incorporate stricter measures into their data architectures to protect consumer privacy.
Yet many are still in the dark about data privacy in big data, compliance with data privacy laws, and how these affect big data stores. This post aims to give big data professionals the foundational knowledge they need to meet their data privacy compliance responsibilities, covering several key concepts and offering tips on how to put data compliance into practice.
What Is Data Compliance?
Data compliance is often confused with other terms, such as data privacy, data protection and cybersecurity. But it has its own clear and distinct meaning.
It is specifically concerned with ticking the right boxes, where you implement the required procedures and technologies to meet data protection regulations and standards.
These measures are designed to help safeguard personal data, which includes:
- personally identifiable information such as the name, email address or telephone number of an individual
- sensitive personal information such as details about someone’s sex life, religion or ethnic origin
When working with big data, compliance with these can be challenging simply due to the size of the data sets involved.
The Cloud’s Shared Responsibility Model
Data security is one of the fundamental components of all data protection legislation. When IT was exclusively the domain of the on-premises data center, this was your sole responsibility. But what about your big data systems deployed to the cloud? In this case, you share the responsibility for security with your cloud service provider.
A shared responsibility model is a structured framework, used by cloud vendors, such as AWS and Microsoft Azure, to help cloud customers understand the security obligations of each party. Although all shared responsibility models follow the same fundamental principles, they take different approaches to clarify each party's responsibilities.
For example, Amazon's model is remarkably simple:
- Security of the cloud: Security responsibilities that fall to Amazon, such as the hardware, host operating system and physical security of its facilities.
- Security in the cloud: Aspects of security that remain your responsibility, such as your own application software and guest operating systems.
By contrast, Microsoft Azure goes into more detail, explaining how the vendor takes more of the responsibility for security as you progress from its IaaS, through PaaS, to its SaaS offerings. This highlights the significant role fully managed solutions can play in reducing the burden of security in big data architectures.
Google Cloud Platform doesn't formally publish a shared responsibility model. However, in its recent security foundations guide, the vendor provided a matrix of shared security responsibility for workloads in the cloud.
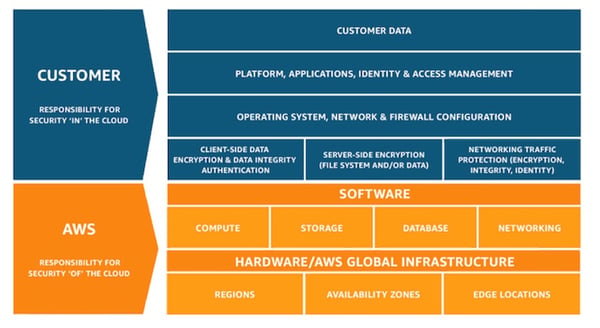 AWS Shared Responsibility Model: Source AWS
AWS Shared Responsibility Model: Source AWS
Well-Architected Framework
A well-architected framework is a modular series of implementation guidelines that leading cloud vendors, including AWS, Microsoft Azure and Google Cloud Platform, publish to help customers optimize their cloud deployments in line with best practices.
These frameworks provide a structured approach to configuring and maintaining a scalable, efficient, secure, and resilient cloud.
They can therefore aid compliance by helping big data professionals to build solutions based on solid foundations, which make provision for strong governance, robust network topology, and vulnerability management.
Big Data Compliance in Practice
Data Security
To comply with data privacy compliance regulations, such as the General Data Protection Regulation (GDPR) and South Africa’s Protection of Personal Information Act (POPIA), you must put in place appropriate technical and organizational measures to protect personal data. This applies to your NoSQL databases and nodes in your data lake just as much as it does to your traditional relational databases.
You should start by encrypting your data at rest so it’s unreadable in the event of exposure or theft. In addition, you should use transport layer security (TLS) to protect data in transit between users, servers and cluster nodes.
Encryption can potentially affect the performance across your big data system. However, if you configure it correctly, it should have relatively little impact. Also be aware that your data is only as secure as the keys you use to encrypt it. So good key management is essential.
And, finally, don't forget to incorporate other security precautions into your big data platform. These should typically include measures such as automated software updates and patches, access control, identity management and a cloud-based security information event management (SIEM) system.
Transparency
Data privacy laws generally include transparency rules that grant citizens the right to be informed about the use of their data.
So, where you collect personal data about individuals, you must provide information such as:
- who you are
- what information you collect
- how long you intend to retain it
- the purpose for which you process it
If you’re analyzing data harvested from another application then your organization will be using it for more than one purpose. So you’ll need to reflect this in your privacy policy and consent notices.
At the same time, these details must be concise, easily understood and in simple, everyday language. This may prove challenging, as big data analytics is a difficult concept to explain. So you'll need to work carefully with legal and compliance teams to ensure the wording of your company's privacy policy is sufficiently clear and transparent for general public consumption.
Data Minimization
Data minimization is a core principle of virtually all data protection laws. It basically means you should only collect the minimum amount of personal data you actually need to fulfill its purpose. This may appear to conflict with the very essence of big data, where the more information you have at your disposal, the better.
But, by and large, you shouldn’t need personal data for analytics. So, if you can get all the insights you need without it then there's really no point in importing it into your big data platform. You’ll then not only meet data privacy compliance requirements but also streamline your data, thereby helping to reduce storage costs and potentially increase performance.
In other words, unless you have a clearly stated purpose outlined in your online privacy policy, you should avoid processing personal data by filtering it out in the data preparation or, ideally, data ingestion process. However, it's important you make data scientists aware that you've pared down any data—so they have a clear picture of what information is available.
Right of Access
New privacy laws have strengthened citizens’ rights to access, change or delete the data you hold about them. This includes their personal information stored and processed in your big data systems.
Compliance teams therefore need to know what personal data you maintain about an individual in order to provide an accurate and comprehensive response to a right-of-access request. Under many data protection laws, they must serve such requests without delay and within very specific time limits.
However, this is no easy challenge given the sheer volume and unstructured nature of content ingested into data lakes. Despite that challenge, your big data analytics system should take right of access into consideration by allowing for quick retrieval, correction, or erasure of a data subject’s information.
Good inventory management will therefore play a critical role in meeting your compliance obligations, as well as tools that can identify, understand and retrieve data about a specific person in any kind of big data repository.
Data Transfer
Privacy laws across the world each have their own set of rules governing cross-border transfer of personal data. For example, the GDPR only permits transfers out of the European Economic Area (EEA) to countries with data privacy compliance frameworks that provide adequate protection of personal information.
But a big data solution will often ingest data from a variety of cloud regions. So you’ll need to carefully evaluate and map your data flows for potential compliance issues. Where necessary, you’ll need to adapt to compliance requirements by either restricting the movement of personal data or revising your consent and privacy notices.
The Cost of Non-Compliance
Data compliance can present significant challenges to modern enterprise IT. When it comes to big data, compliance with the major data privacy laws around the globe presents analysts with multiple regulations that will dictate how and where data can be stored.
The cost of non-compliance can be huge—in terms of not only stiffer penalties for breaches of regulations such as the GDPR, but also reputational damage and the effect it would have on the bottom line. That’s why it’s essential to incorporate privacy into your big data architectures and thereby avoid risks your organization cannot afford to take.
To help ensure your big data stores are compliant with the latest data privacy regulations.